谷歌最强开源模型Gemma 2发布,270亿参数奇袭Llama 3,单张A100可全精度推理
来源:谷歌DeepMind | 发布时间:2024-06-28
摘要:谷歌在I/O Connect大会上放大招,公布其新一代最强开源模型——Gemma 2。
谷歌在I/O Connect大会上放大招,公布其新一代最强开源模型——Gemma 2。
Gemma 2有90亿(9B)和270亿(27B)两种参数规模可用。27B模型训练了13T tokens,9B是8T tokens,都拥有8192上下文窗口,可在Google AI Studio中使用。26亿参数(2.6B)模型将很快发布,小到可以在手机本地运行。
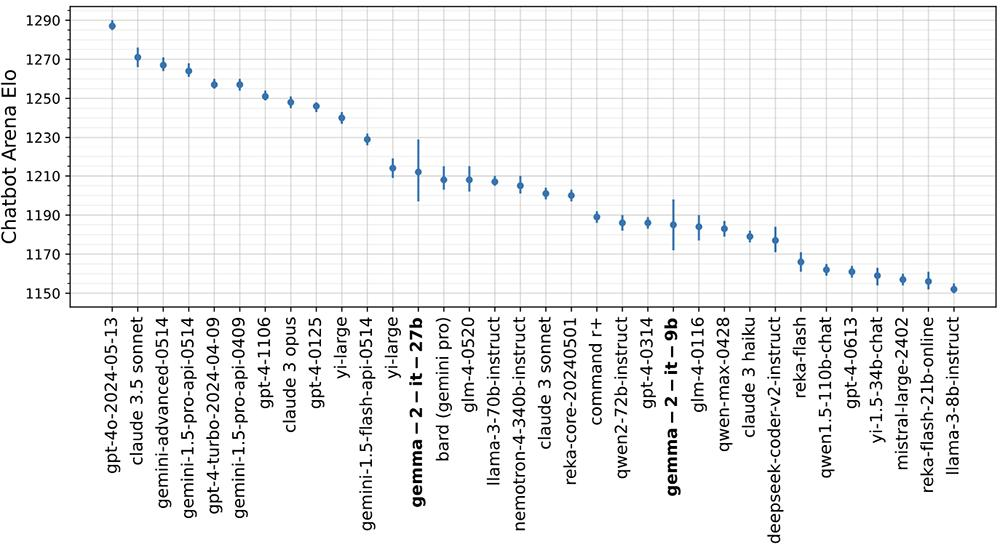
在盲测大语言模型竞技场LMSYS Chatbot Arena中,270亿参数的Gemma 2指令微调模型击败了拥有700亿参数的Llama 3,并超过Nemotron 4 340B、Claude 3 Sonnet、Command R+、Qwen 72B等模型,在所有开源权重的模型中位列第一;9B模型则是当前15B以下参数的模型中成绩最好的。
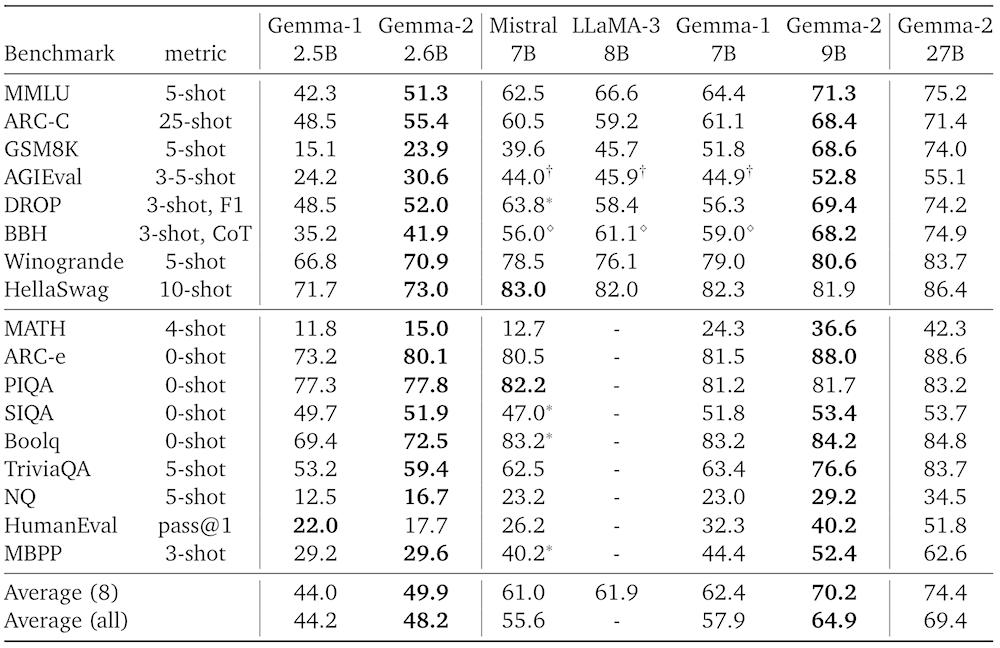
谷歌在今年早些时候推出轻量级先进开源模型Gemma,只有2B和7B参数版本,下载量超过1000万次。Gemma 2涵盖从20亿到270亿参数,比第一代性能更高、推理效率更高,并且显著改进安全性。这是该系列模型迈出的一大步。
270亿参数的Gemma 2提供了与两倍以上参数的模型竞争的替代方案,提供了直到去年12月才可能实现的性能,而且可以在单个英伟达A100/H100 Tensor Core GPU或TPU主机上以全精度高效运行推理,大大降低了部署成本。

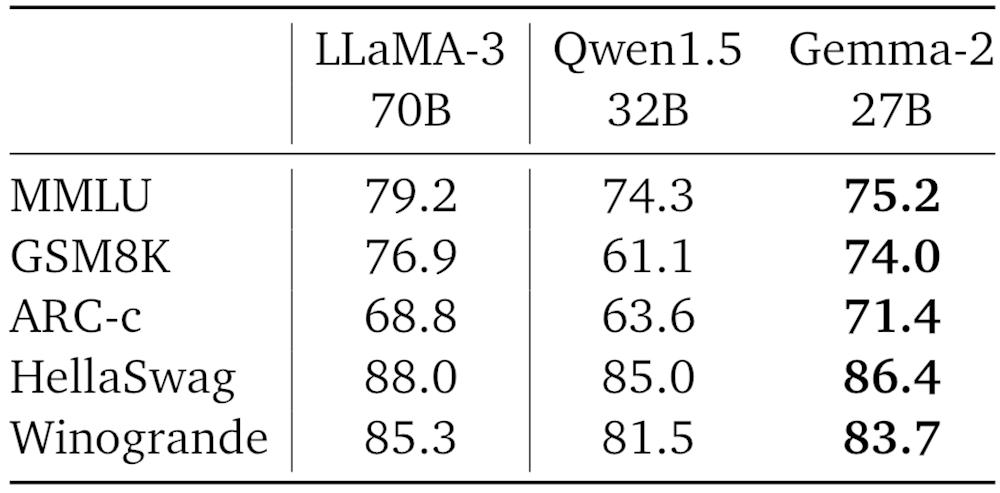
在Hugging Face的基准上,谷歌将Gemma 2 27B与具有类似尺寸的Qwen1.5 32B进行了比较,还报告了Llama 3 70B的性能。Gemma 2 27B的尺寸只有Llama 3 70B的40%,训练数据少到Llama 3 70B的2/3。结果显示,Gemma 2 27B优于Qwen1.5 32B,比Llama 3 70B低几个百分点。
1.重新设计架构,Gemma 2有三大特点
Gemma 2的技术报告共15页,介绍了其架构的多项技术改进,包括交替使用局部-全局注意力机制和分组查询注意力,还使用知识蒸馏而不是下一个token预测来帮助训练较小的2B和9B模型。
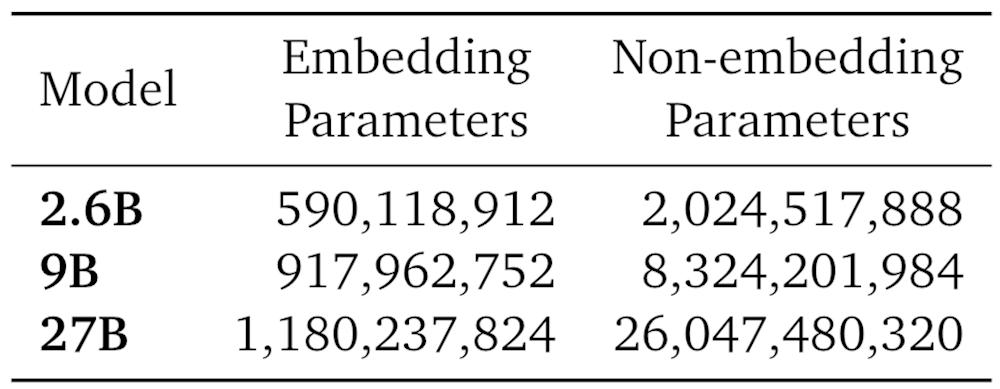
▲Gemma模型的参数量
2.6B模型在一个TPUv5e集群的2x16x16配置上训练,总共用了512张芯片。9B模型在TPUv4集群的8x16x32配置上训练,总共4096张芯片。27B模型在TPUv5p集群的8x24x32配置上训练,总共用了6144张芯片。
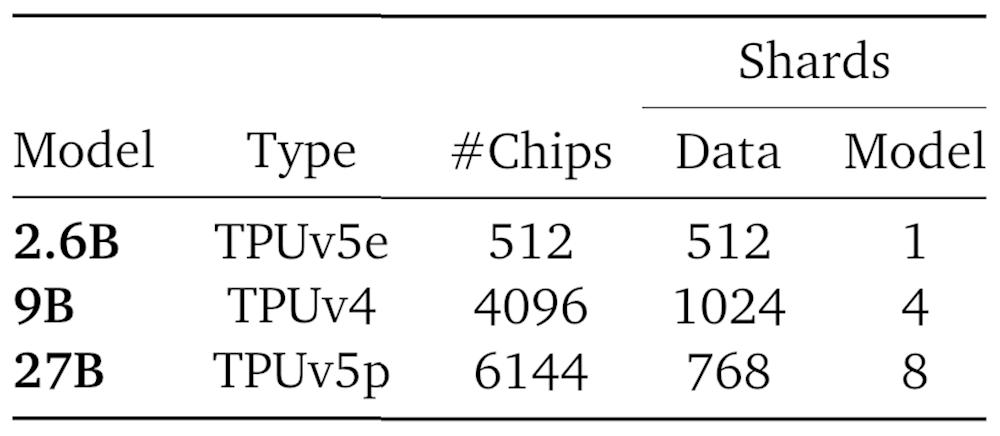
▲用切分训练基础设施
针对更高的性能和推理效率,谷歌在重新设计的架构上构建了Gemma 2。该模型采用与Gemma 1.1相似的算法配方,但用了更多的teacher监督并执行了模型合并。在编程、数学、推理、安全等能力上,Gemma 2都比1.1版本提升显著。
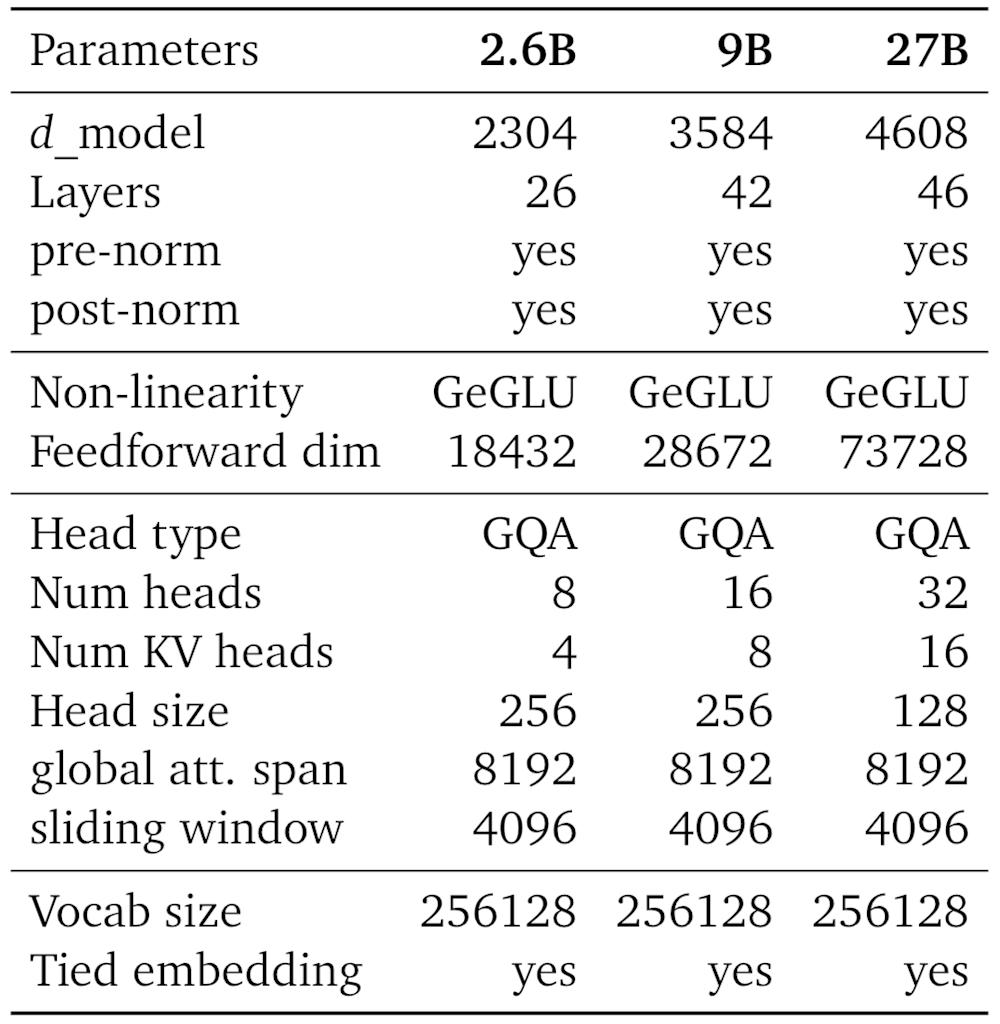
▲主要模型参数及设计选择的概述
结果,Gemma 2模型在其规模上提供了最佳性能,甚至提供了与大2-3倍的模型竞争的替代方案。以下是其突出的特点:
(1)卓越性能:Gemma 2 27B在其同类大小中提供了最佳性能,甚至提供了与两倍以上大小的模型竞争的替代方案。Gemma 2 9B模型也提供了领先的性能,超过了Llama 3 8B和其他同类大小的开源模型。
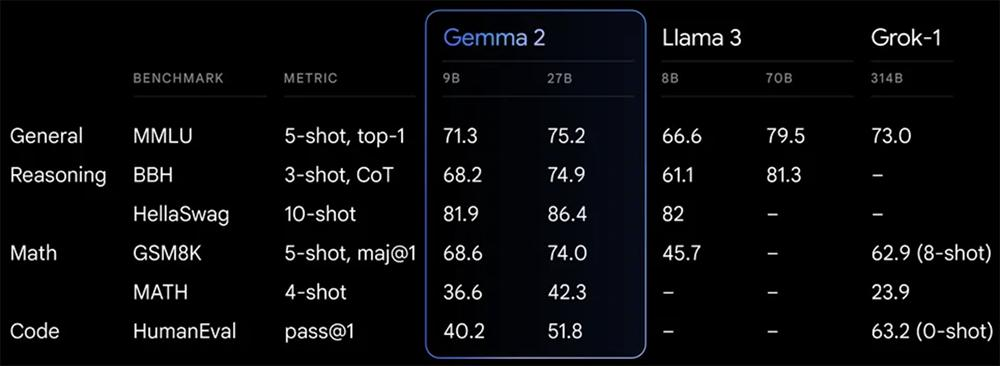
谷歌在各种基准上比较2.6B、9B及27B模型,报告了可以与Llama 3进行比较的8个基准测试的平均性能,以及所有基准测试的平均性能。Llama 3 8B的数据来自HuggingFace leaderboard或其博客。
在MMLU上,9B模型得分为71.3,27B模型为75.2;在AGIEval上,9B模型得分52.8,27B模型得分55.1;在HumanEval上,9B模型得分40.2,27B模型得分51.8。
(2)无与伦比的效率和成本节省:Gemma 2 27B模型设计用于在单个谷歌云TPU主机、英伟达A100 80GB Tensor Core GPU或H100 Tensor Core GPU上高效运行全精度推理,在保持高性能的同时显著降低成本。这使得AI部署更加易于访问和经济实惠。
(3)各种硬件的快速推理:Gemma 2经过优化,可以在各种硬件上以令人难以置信的速度运行,硬件从功能强大的游戏笔记本电脑和高端台式机到基于云的设置。在Google AI Studio中以全精度试用Gemma 2,在CPU上使用Gemma.cpp的量化版本解锁本地性能,或在家用计算机上通过Hugging Face Transformers在英伟达RTX或GeForce RTX上试用。
2.支持商业化,兼容广泛框架,方便部署
Gemma 2为开发者和研究人员构建,其设计更容易集成到工作流程中:
(1)开放且可访问:与原始Gemma模型一样,Gemma 2也是根据谷歌具有商业友好的Gemma许可发布的,允许开发人员和研究人员分享和商业化他们的创新。
(2)广泛的框架兼容性:Gemma 2兼容主要的AI框架,如Hugging Face Transformers,以及通过原生Keras 3.0、vLLM、Gemma.cpp、Llama.cpp和Ollama的JAX、PyTorch和TensorFlow。此外,Gemma优化了英伟达TensorRT-LLM以在英伟达加速基础设施上运行或作为英伟达NIM推理微服务运行。用户可以使用Keras和Hugging Face进行微调。谷歌正在积极努力实现更多参数高效的微调选项。
(3)轻松部署:从下个月开始,谷歌云客户将能轻松在Vertex AI上部署和管理Gemma 2。
新的Gemma Cookbook是一个包含实用示例和指南的集合,引导用户构建自己的应用程序并为特定任务微调Gemma 2模型。
3.提供负责任的AI开发资源,严格测试评估模型安全性
在负责任的AI开发方面,谷歌提供负责任地构建和部署AI所需的资源,包括负责任的生成式AI工具包。最近开源的LLM Comparator帮助开发者和研究人员深入评估语言模型。
即日起,用户可使用配套的Python库与自己的模型和数据进行比较评估,并在应用程序中可视化结果。此外,谷歌正在积极致力于开源文本水印技术SynthID,用于Gemma模型。
在训练Gemma 2时,谷歌遵循内部安全流程,过滤了训练前的数据,并针对一套全面的指标进行了严格的测试和评估,以识别和减轻潜在的偏见和风险。谷歌在与安全性和代表性危害相关的大量公共基准上公布了其结果。
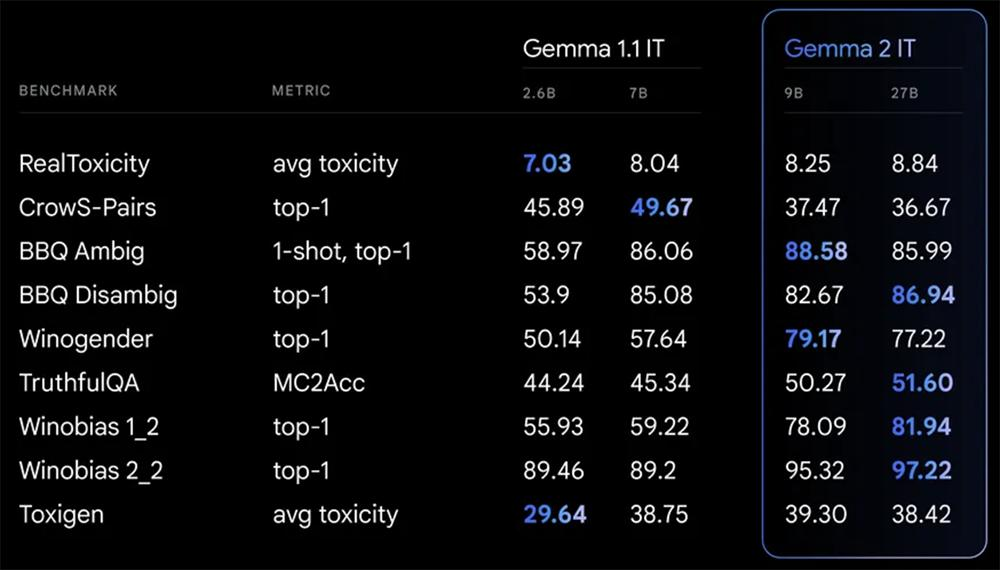
▲Gemma 2 IT模型和Gemma 1.1 IT模型的安全学术基准结果
4.结语:大模型研发趋于实用主义
谷歌Gemma 2的研究进展反映了当前大模型研究趋势,即探索用更轻量级的、更实用的模型来实现更强的性能,并确保易部署,以更好地满足不同的用户需求。
谷歌为开发者和研究人员提供了使用这些模型的多种途径。Gemma 2现可在Google AI Studio中使用,可在没有硬件要求的情况下测试其270亿参数的全部性能,也可以从Kaggle和Hugging Face Models下载Gemma 2的模型权重,Vertex AI Model Garden即将推出。
通过Gemma 2,谷歌证明了蒸馏是训练此类模型的有效方法,基于输出概率的训练能够比纯粹的下一个token预测产生更多的效果。模型仍存在局限性,需要未来研究来持续优化事实性、对抗性攻击的鲁棒性以及推理和一致性。
为支持研究和开发,Gemma 2还可通过Kaggle免费获得,或通过Colab笔记本的免费层获得。首次使用谷歌云服务的用户可能有资格获得300美元的积分。学术研究人员可以申请Gemma 2学术研究计划,以获得谷歌云积分,加速对Gemma 2的研究。申请截止日期为8月9日。