阿里云Qwen2.5发布!再登开源大模型王座,Qwen-Max性能逼近GPT-4o
来源:机器之心 | 发布时间:2024-09-23
摘要:在云栖大会上,阿里云发布新一代开源模型Qwen2.5,包括性能超越Llama 3.1-405B的Qwen2.5-72B,及多尺寸语言、数学、代码和多模态模型,共计上百款。Qwen2.5系列在多个基准测试中取得优异成绩,支持多语言和长达128K的上下文处理。旗舰模型Qwen-Max性能接近GPT-4,在数学和代码能力上甚至超越GPT-4,多项能力大幅提升,尤其在人类偏好对齐上实现显著进步。
2023 年 8 月,通义首次开源后迅速引起全球开发者的关注和热议,短短一年时间内,阿里云大模型又迎来了重要升级。
在 9 月 19 日的云栖大会上,CTO 周靖人宣布:通义千问发布新一代开源模型 Qwen2.5,开源旗舰模型 Qwen2.5-72B 性能超越 Llama 3.1-405B,再次登上全球开源大模型的王座;通义旗舰模型 Qwen-Max 全方位升级,性能已经逼近 GPT-4o。

发布现场,图源:泽南
通义千问凭借不断迭代的技术和丰富的应用场景,迅速崛起为开发者的热门选择,尤其是在中文社区中引发了广泛关注。这次发布,模型不仅展现出更强大的代码、数学和语言处理能力,还拥有领先的多模态处理和视觉智能,使其成为当前 AI 技术领域的佼佼者。
百宝箱:Qwen2.5
这次,Qwen2.5 系列是一个超级 AI 模型「百宝箱」,涵盖了多个尺寸的大语言模型、多模态模型、数学模型和代码模型。每个尺寸都有基础版本、指令跟随版本和量化版本,总计上架了 100 多个模型,刷新了业界纪录。
集合链接:https://huggingface.co/collections/Qwen/qwen25-66e81a666513e518adb90d9e
在语言模型方面,Qwen2.5 开源了 7 个尺寸:0.5B、1.5B、3B、7B、14B、32B、72B,每个都在同等参数赛道创造了业界最佳成绩。这些型号的设定充分考虑了下游场景的不同需求:3B 是适配手机等端侧设备的黄金尺寸;32B 是最受开发者期待的「性价比之王」,可在性能和功耗之间获得最佳平衡。令人惊喜的是,Qwen2.5-32B 的整体表现甚至超越了 Qwen2-72B。
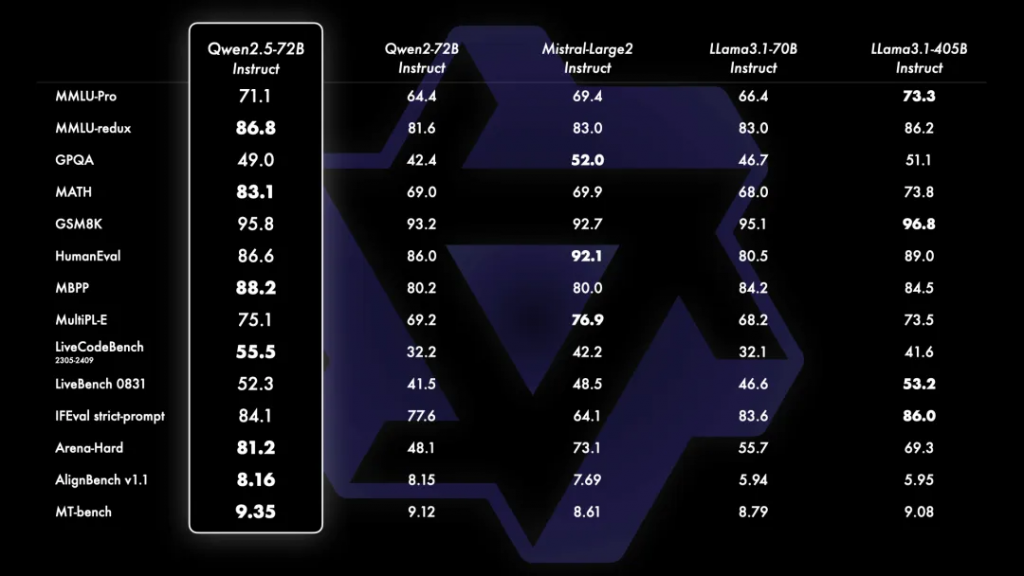
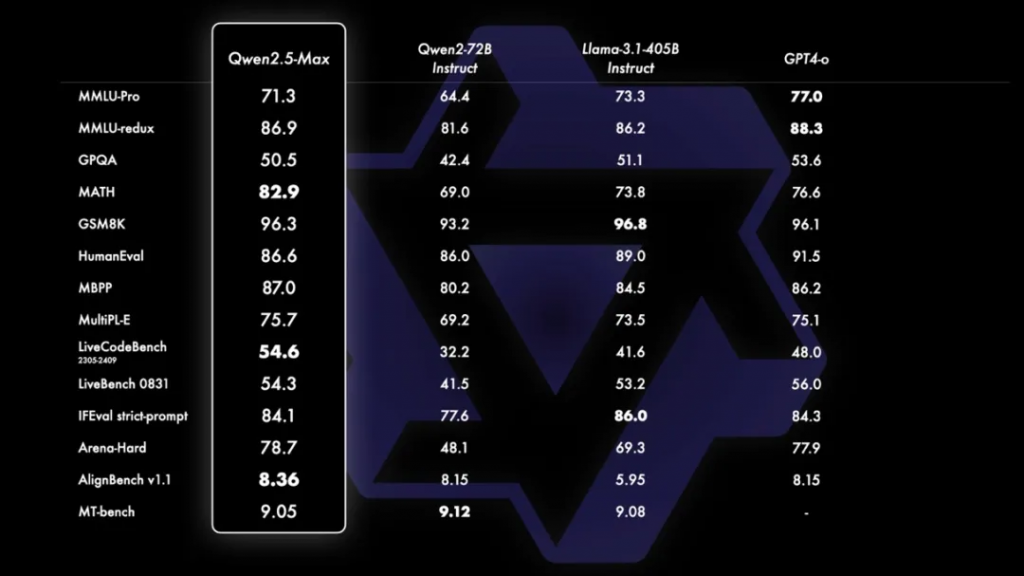
所有 Qwen2.5 系列模型都在 18 万亿(18T)tokens 的数据上进行了预训练。相比 Qwen2,整体性能提升了 18% 以上,拥有更多的知识、更强的编程和数学能力。旗舰模型 Qwen2.5-72B 在 MMLU-redux(通用知识)、MBPP(代码能力)和 MATH(数学能力)等基准测试中,分别取得了 86.8、88.2、83.1 的高分。72B 作为 Qwen2.5 系列的旗舰模型,在多个核心任务上,以不到 1/5 的参数超越了拥有 4050 亿巨量参数的 Llama3.1-405B。
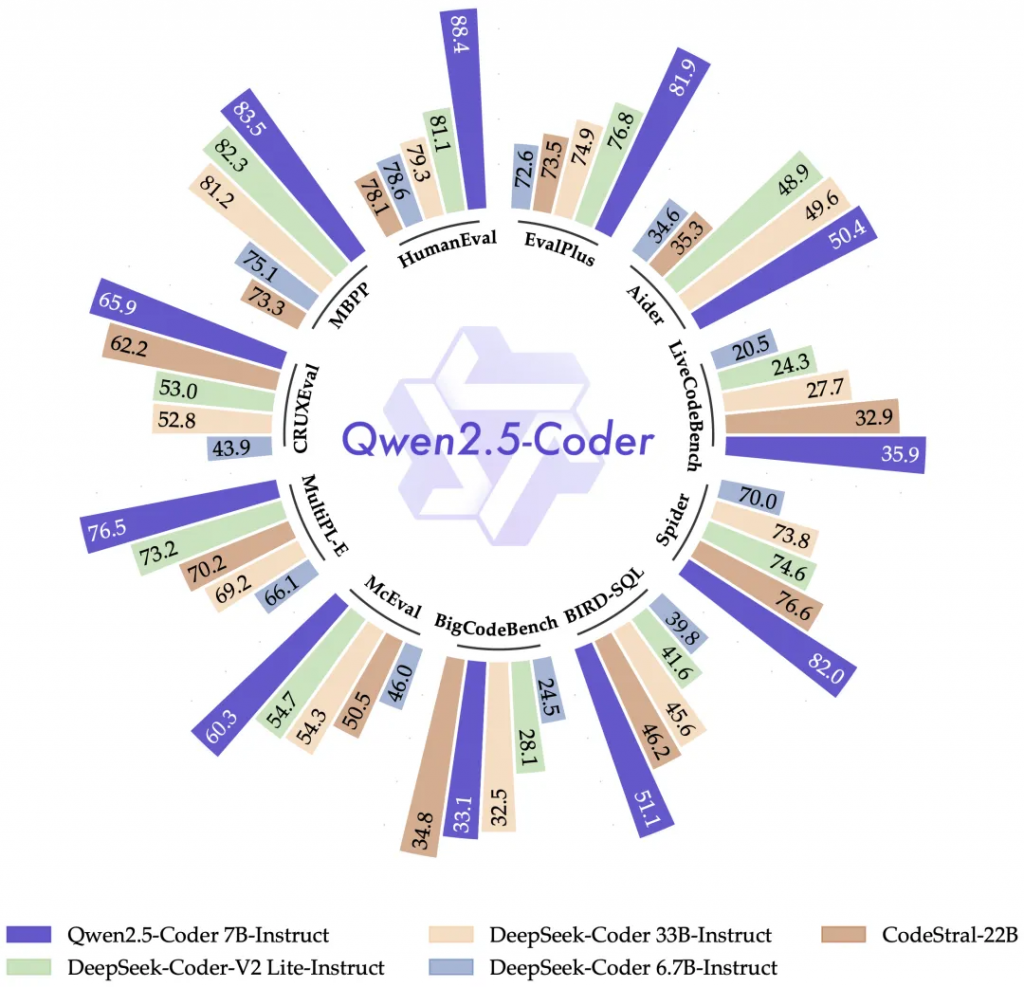
在专项模型方面,用于编程的 Qwen2.5-Coder 和用于数学的 Qwen2.5-Math 都有了实质性飞跃。
Qwen2.5-Coder 在多达 5.5 万亿(5.5T)token 的编程相关数据上进行了训练,当天开源了 1.5B 和 7B 版本,未来还将开源 32B 版本。Qwen2.5-Math 支持使用思维链和工具集成推理(TIR)解决中英双语的数学题,是迄今为止最先进的开源数学模型系列。本次开源了 1.5B、7B、72B 三个尺寸和一款数学奖励模型 Qwen2.5-Math-RM。
Qwen2.5 模型支持高达 128K 的上下文长度,最多可生成 8K 的内容。它们还拥有强大的多语言能力,支持中文、英文、法文、西班牙文、俄文、日文、越南文、阿拉伯文等 29 种以上语言。
在多模态模型领域,备受期待的视觉语言模型 Qwen2-VL-72B 正式开源!Qwen2-VL 具备强大的视觉理解能力,能够识别不同分辨率和长宽比的图片,还可以理解长达 20 分钟以上的视频内容。同时,它还支持自主操作手机和机器人的视觉智能功能,展现了高度灵活的应用场景。
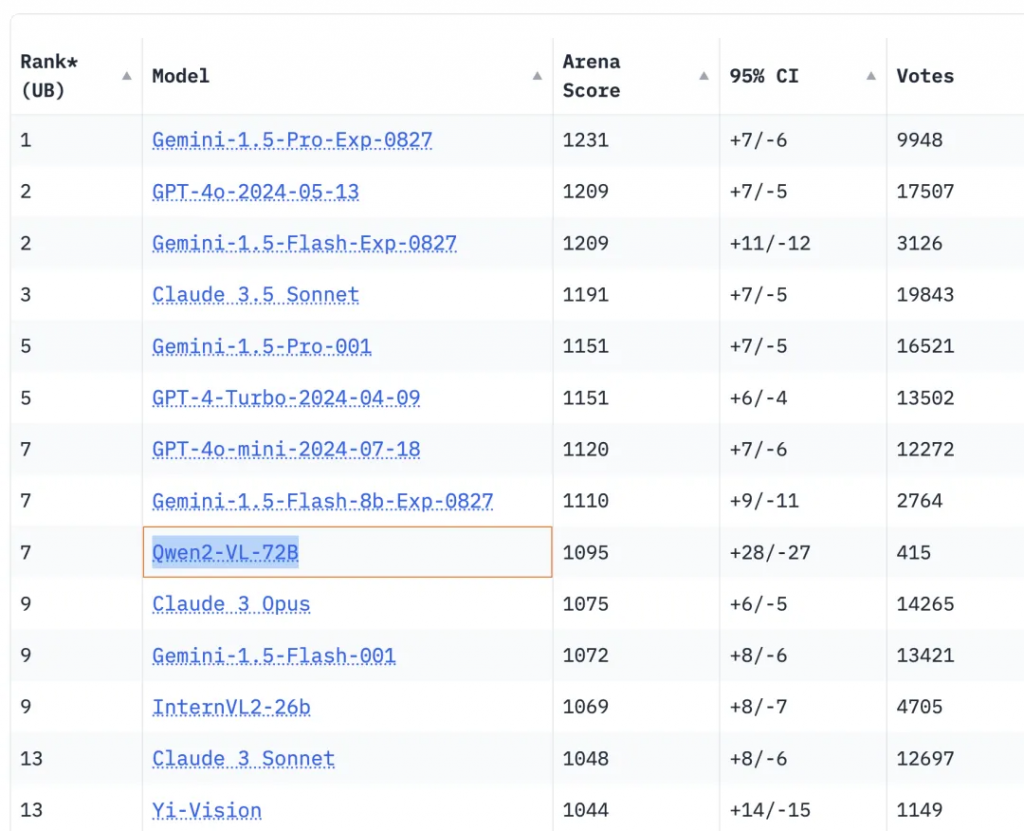
Qwen2-VL-72B 在权威测评 LMSYS Chatbot Arena Leaderboard 成为全球得分最高的开源视觉理解模型
Qwen-Max 全方位升级
现在,通义官网和通义 APP 的后台模型都已切换为 Qwen-Max,继续为所有用户免费服务。你还可以通过阿里云百炼平台调用 Qwen-Max 的 API,亲自体验它的强大实力。
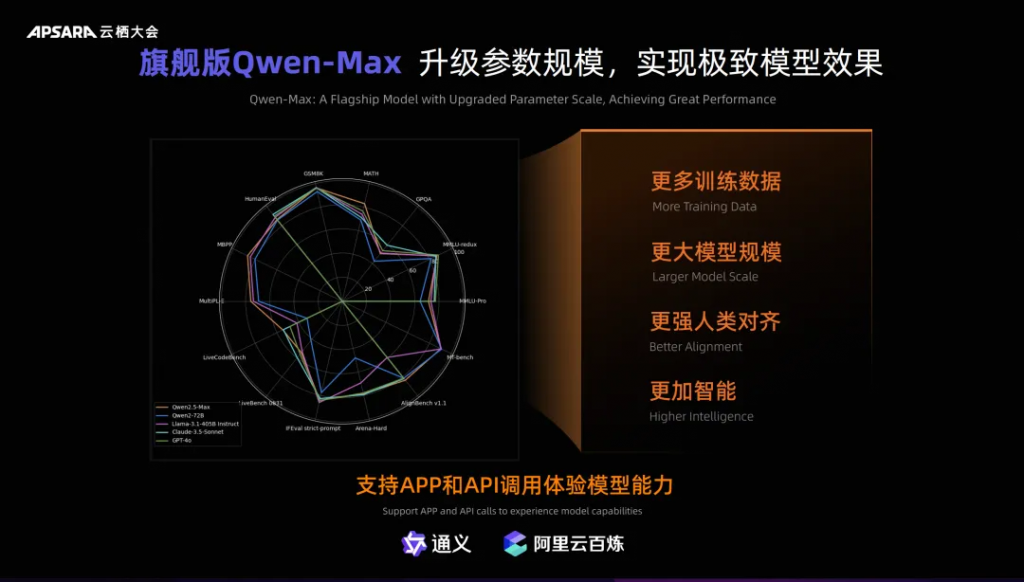
那么,Qwen-Max 到底有多厉害呢?
相比上一代模型,它在训练中使用了更多的训练数据、更大的模型规模,并进行了更深入的人类对齐,最终实现了智能水平的飞跃。在 MMLU-Pro、MATH、GSM8K、MBPP、MultiPL-E、LiveCodeBench 等十多个权威基准测试中,Qwen-Max 的表现已经接近 GPT-4o,尤其是在数学能力和代码能力上,甚至超越了 GPT-4o!要知道,数学和代码所代表的推理能力可是大模型智能的核心体现。
更令人兴奋的是,与 2023 年 4 月的初代通义千问大模型相比,Qwen-Max 的理解能力提升了 46%、数学能力提升了 75%、代码能力提升了 102%、抗幻觉能力提升了 35%、指令遵循能力提升了 105%。还有一个更加惊喜的数据,模型与人类偏好的对齐水平实现了质的飞跃,提升了 700% 以上。这意味着 Qwen-Max 不仅更聪明,还更懂你!