摘要:随着ChatGPT的爆火,该技术引爆了人工智能产业。该语言模型既能写诗歌、编代码,还能创造剧本、面试出题、发表论文,呈现出解放人类生产力的惊人特质。
ChatGPT引起了大厂、投资人、学界、业界各领域人士的关注。AI公司全面入局,引发了资本市场震荡……生物医药领域是否能和这类新兴技术结合?目前都有哪些应用?
ProGen:生物界「ChatGPT」
首次实现从零合成全新蛋白
近期,一家刚刚成立三年的初创公司Profluent,首次利用深度学习语言模型合成了自然界不存在的全新蛋白质,极大加速蛋白质工程的研究。
科学家们采用类似ChatGPT的蛋白质工程深度学习语言模型——ProGen,首次实现了AI预测蛋白质的合成。这些蛋白质不仅与已知的完全不同,相似度最低的甚至只有31.4%,但和天然蛋白一样有效。目前,这项工作已经正式发表于Nature子刊。
Profluent创始人CEO Ali Madani表示,Profulent已经设计出了多个家族的蛋白质。这些蛋白质的功能与样本蛋白(exemplar proteins)一样,因此是具有高活性的酶。这项任务非常困难,是以zero-shot的方式完成的,这意味着并没有进行多轮优化,甚至根本不提供湿实验室的任何数据。而最终设计出的蛋白质,是通常需要数百年才能进化出来的高活性蛋白质。
ProGen是一个12亿参数的条件蛋白质语言模型,其基于Transformer架构,通过自注意机制来模拟残基的相互作用,并且可以根据输入控制标签生成不同的跨蛋白质家族的人工蛋白质序列。Progen的算法也与ChatGPT背后的模型GPT3.5类似,它通过学习氨基酸如何组合成2.8亿个现有蛋白质的语法,学会了如何生成新的蛋白质。
Madani表示:“就像ChatGPT学习英语之类的人类语言一样,我们是在学习生物和蛋白质的语言。”值得注意的是,还有一些初创公司也在尝试相似的技术,比如Cradle,以及Flagship Pioneering的Generate Biomedicines等。
BioGPT:提高科研效率的得力工具
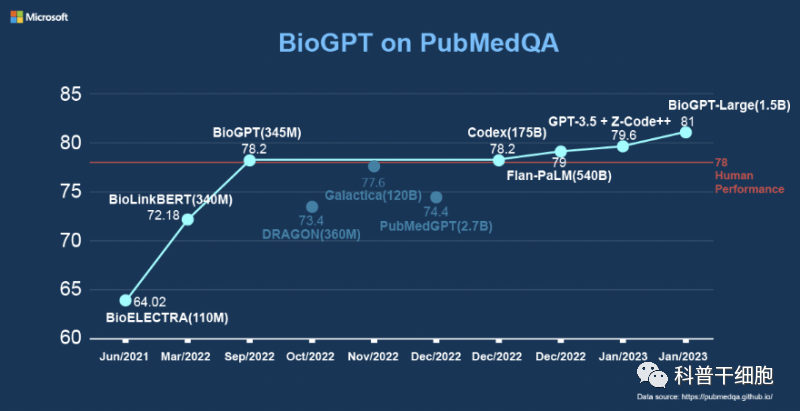
随着科学技术突破,研究人员对大量生物医药文献采用了多种机器学习技术,在各大生物医药出版物及科研论文中使用文本挖掘和信息提取,对开发新药物、临床治疗、病理学研究至关重要。从这些海量材料提取有意义的信息,就是BioGPT发挥作用的地方,它在科学文献网站PubMed上超过1500万篇摘要的庞大语料库上进行了预训练,可以根据用户的提问迅速提供相关的答案。在PubMedQA检测中,这款人工智能模型达到81.0%的准确性。
通用语言领域中预训练模型主要有两个分支——GPT和BERT及其变体,BERT在生物医药领域受到的关注最多,比如BioBERT和PubMedBERT是生物医药领域中最常受到关注的两个预训练语言模型。然而,BERT模型更适合理解任务,而不是生成任务。而微软研究人员推出的BioGPT使用了六项生物NLP任务来评估语言模型,其中包括问答、文档分类和端到端关系提取。能够帮助我们大幅度提高从科学文献中获得信息的速度。
火爆之下,仍有隐忧
虽然ChatGPT或类似的语言模型能在生物医药领域能够得到广泛应用,但仍有隐忧。首先,ChatGPT没有联网,因此并不能替代搜索引擎。它无法访问最新的事件进展,因为其当初在进行模型训练时,数据只更新到2021年,而科研技术日新月异,为了保持预训练语言模型在生物医药领域的准确性,需要实时更新数据或联网。其次,因为ChatGPT接受的是大量数据的训练,有时可能会生成包含冒犯性或不恰当语言的回复。这是利用训练数据生成文本的算法的局限性之一。例如科技媒体CNET曾曝出,ChatGPT编写的77篇内容中,41篇有错误,目前,平台已予以更正,并表示将暂停此种方式生产内容。
Nature也对此问题表达了重视,这家权威的学术出版机构表示,学研圈都在担心,学生及研究者们可能会以大型语言模型生成的内容当作本人撰写的文本,除却冒用风险外,上述过程还会产生不可靠的研究结论。
Nature针对ChatGPT代写学研文章、被列为作者等一系列问题,给了定性。具体来说,有两个原则。第一,任何大型语言模型工具(比如ChatGPT)都不能成为论文作者;第二,如在论文创作中用过相关工具,作者应在“方法”或“致谢”或适当的部分明确说明。
尽管ChatGPT没有彻底改变我们现有的生产方式,但其发展仍然是令人欣喜的。人工智能对生物医药领域的介入不仅有望帮助诊断重大疾病,而且能够提高研发的效率,如何正当的使用新兴工具,将决定我们的未来。
{kind=link}
{kind=link}
{kind=link}
{kind=link}