英伟达:超级工厂是怎样炼成的
来源:浙商证券 | 发布时间:2024-04-17
摘要:英伟达作为全球领先的GPU算力龙头,自上市以来收入与市值显著增长,凭借GPU+CPU+DPU的三芯布局,构筑了全面产品矩阵,并布局游戏、数据中心、专业可视化、自动驾驶四大市场。在游戏业务上引领行业发展,数据中心业务成为长期增长点,专业可视化领域保持领先。随着大模型兴起,公司正加速发展以满足巨型人工智能和高性能计算需求。
一、英伟达:全球算力王者,加速计算时代的AI超级工厂
1.1上市以来收入成长超160倍,市值增长超2700倍
公司是全球领先的GPU算力龙头。公司于1993年由JensonHuang(黄仁勋)及来自于SunMicrosystem的两位工程师ChrisMalachowsky和CurtisPriem创立,专注图形计算芯片的设计与研发,公司经历了起步积累、困境反转、转型升级和快速成长四个阶段,并成长为全球AI算力领军,根据Gartner预计,公司在全球AI芯片市场的市占率最高已经达到90%。
1.2三芯片四领域,构筑全面产品矩阵
基础芯片层面,公司基于GPU技术路线,通过自研+并购形成GPU+CPU+DPU的三芯布局:(1)2000年推出全球首款GPU以来不断进行迭代升级,目前GPU领域产品涵盖消费级、工作站级、移动级到高性能计算的多种类型,即将在2024Q2出货的H200TensorCoreGPU基于NVIDIAHopper™架构,FP16下算力达到989TFLOPS,同时是首款提供HBM3e的GPU,以每秒4.8TB的速度提供141GB内存,与前身A100相比容量几乎翻倍,带宽增加2.4倍,针对GPT-3模型的推理性能是A100的18倍;(2)2020年收购Mellanox后推出的BlueFieldDCU能够有效减少CPU负荷,提升整体系统性能,BlueField-3DPU与上一代相比,具备2倍的网络带宽、4倍的计算能力和几乎5倍的内存带宽,能够以高达8倍的速度运行工作负载,同时降低TCO并提高数据中心能效;(3)2021年推出的自研Grace系列CPU超级芯片基于ARMv9架构设计,相较于现有数据中心使用的x86CPU,运行微服务的速度快2.3倍,内存密集型数据处理性能快2倍,在多个技术计算应用上运行流体力学计算工作时速度快1.9倍;为了进一步满足巨型人工智能和高性能计算工作负载的需求,公司还发布了将GraceCPU和HopperGPU封装在一起的GraceHopperSuperchip,以及将两个GraceCPU在同一款PCB上互联的GraceSuperchip;
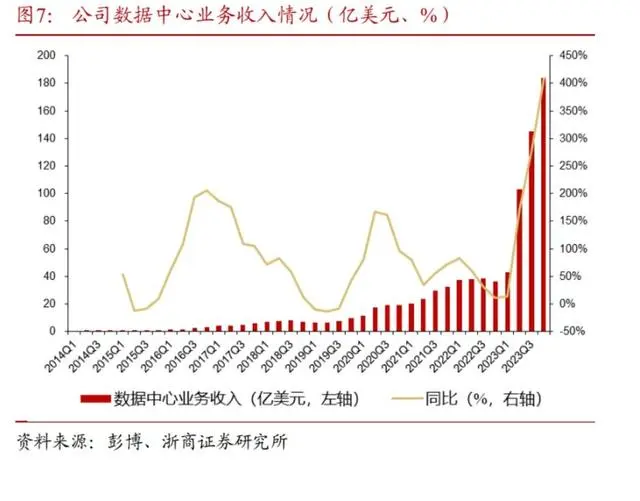
行业客户层面,公司布局了游戏、数据中心、专业可视化、自动驾驶市场四大领域:(1)数据中心:公司2016年至今以及未来长期的增长点。公司为云厂商(CSP)、企业、公共部门的数据中心、智算中心、超算中心提供基于CPU+GPU+DPU芯片、IB+以太网等网络设备的硬件系统,以及AI加速库、开发工具、应用等软硬件一体的解决方案;随着云端数据中心需求的爆发以及公司三芯布局的形成,公司数据中心业务近五年收入复合增速高达74.56%、近三年复合增速高达92.18%,2023年全年实现收入475.25亿美元,同比+216.73%,其中2023Q4实现收入184.04亿美元,同比+409%;公司自2011年的TeslaM2090开始不断更新迭代数据中心产品,下一代B100采用Blackwell架构,将使用台积电的4nm工艺,与现有采用Hopper架构的H200系列相比,性能提升超过100%。
(2)游戏业务:公司的起家业务和基本盘,以先进技术引领行业发展。公司提供分别面向PC和笔记本的GeForce系列RTX和GTX显卡硬件、可在性能不足的设备上玩PC游戏的GeForceNOW云游戏服务、在电视上播放高质量流媒体的SHIELD服务以及用于游戏机的平台和开发服务;随着挖矿浪潮的兴起以及公司光追系列显卡的推出,公司游戏业务近五年复合增长率达到10.91%,2023年全年实现收入104.82亿美元,同比+15.61%,其中2023Q4实现收入29亿美元,同比+56%,为其他业务提供了稳定的现金流;游戏业务见证了公司的成长史,每一代微架构的升级都带来了性能的显著提升:2018年公司推出的首款支持实时光线追踪的Turing架构GeForceRTX2080显卡,可以在游戏中通过模拟光线的物理行为,实现电影级质量的实时渲染,引领了3A大作发展的方向;公司推出的DLSS(深度学习超级采样抗锯齿)技术在不影响游戏性能的同时,能提供与TAA抗锯齿技术几乎相同的画质,根据快科技测试,RTX2080DLSS的性能领先上一代GTX1080TAA达到了80%。
(3)专业可视化:专业图形领域领导者。公司为独立软件供应商(ISV)合作,为在设计与制造环节与数字内容创作环节的3D艺术家、建筑师和产品设计师等提供从桌面到云端的RTX和Quadro解决方案;随着大模型的兴起,企业工作站也开始进行更新迭代,2023年全年实现收入12.72亿美元,同比-3.56%,其中2023Q4实现收入4.63亿美元,同比+105%。
(4)自动驾驶:前瞻布局的中长期增长业务。公司通过DRIVE系列品牌,为交通运输业构建出软件定义的端到端平台及解决方案,客户可以基于该平台快速高效地开发自动驾驶产品;硬件端包括Orin、Atlan、以及将于2025年投入生产的ThorSOC,软件端包括针对车载加速计算率先推出的安全操作系统OS,针对自动驾驶汽车开发的DriveWorks中间件,包含感知、地图构建和规划层的AV软件栈,AI辅助驾驶平台Chauffeur,为AI驾驶舱创新解决方案提供舱内感知的开放软件平台IX,实现实时对话式AI的Concierge,使用准确的真值地图和可扩展的车队来源地图来创建和更新自动驾驶汽车地图Map等产品;2023年全年实现收入10.90亿美元,同比-17.36%,其中2023Q4实现收入2.81亿美元,同比+24.34%。
1.3三十年专注的高研发投入,奠定高业绩成长基石
与Intel、AMD相比,CUDA软件生态带来的毛利率、净利率优势明显。公司上市以来毛利率及净利率随行业及业务的变化经历了三个阶段:1)上市前至2003年,受公司与微软就Xbox降价问题的影响,公司毛利率从2001年的37.92%下跌至2003年的29.01%、利润率则从12.92%下降至4.08%,后续随着公司与Intel、索尼签单,毛利率、净利率逐步回升;2)2004-2008年,受全球经济危机、研发CUDA初期的技术不成熟影响,当时的G84/G86核心产品出现了过热而导致花屏的“显卡门”事件,公司毛利率从2007年的45.62%下跌至2008年的34.29%,利润率则从19.46%转负为-0.88%,后续随着2009年Fermi架构的GPU推出,毛利率、净利率实现了快速修复;3)2009年至今,在全球经济复苏以及CUDA带来的软件生态优势拉动下,与Intel、AMD相比,公司毛利率、利润率开始呈现明显领先的上升态势,毛利率持续上行从2008年的34.29%提升至2023年的72.7%、净利率也同步从-0.88%大幅提升至48.85%。
公司常年专注投入研发,研发费用处于高位水平。上市以来,公司通过“三团队-两季度”的研发模式以及聚焦GPU研发,实现了在单一领域与友商相比更高的研发投入:1)在1999-2005年与ATI的竞争中,公司的研发费用从1999年的0.32亿美元快速提升至2005年的3.52亿美元,CAGR达到61.54%;2)在2006至今与AMD的竞争中,公司的研发费用从2005年的3.6亿美元快速提升至2023年的86.75亿美元,CAGR达到19.34%;与AMD相比,2005年公司研发投入为AMD的32.73%,而18年后的2023年,公司研发投入已是AMD的1.47倍;同时由于公司聚焦GPU的研发而AMD则需要同时对CPU进行投入并于Intel展开竞争,我们估计2023年在GPU领域的研发投入倍数将大于1.47。
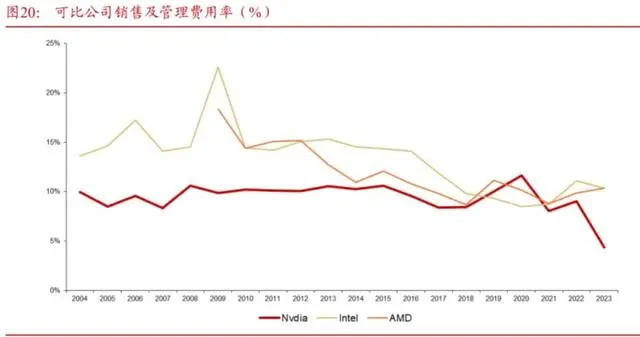
凭借超强的研发投入实现了强大的产品力,销售及管理费用率从常年的10%逐步下降。公司上市以来销售费用率稳定在10%并呈逐步下降趋势;2021年销售及管理费用率从10.01%提升至11.63%,主要原因是收购Mellanox;2023年,由于公司数据中心业务的爆发,公司销售及管理费用率下降至4.36%。
二、历史复盘:用产品定义算力发展史
2.12000年前:从“狂野西部”通用图形计算起步,凭借更加高效的研发模式、绑定大客户微软胜出并定义世界首款GPU
“PreGPU”时期,图形计算芯片技术快速迭代,百家争鸣:上世纪90年代初,高性能图像主要用于图形工作站和视频游戏机中,1995年微软推出的Windows95具备音视频等多媒体功能、大量3D渲染游戏登录PC平台、图形芯片集成度提升推动了3D图像市场的发展;因而“PreGPU”时期的图形计算芯片技术路线经历了单纯辅助CPU进行图形显示、可进行2D加速计算、可进行3D加速计算、具备固定的渲染管线四个阶段,S3、ATI、AMD、英伟达、3DFX等众多大小玩家展开激烈竞争,一度形成“百家争鸣”局面,激烈的市场竞争带来的是图形处理芯片的快速迭代和演进。
英伟达成立初期专注图形计算芯片的PC消费市场:1993年,JensonHuang(黄仁勋)及来自于SunMicrosystem的两位工程师ChrisMalachowsky和CurtisPriem认为个人电脑将会成为游戏、多媒体的主流消费设备,因而共同创立了英伟达(Nvidia),专注于图形计算芯片的设计与研发。1994-2000年公司完成了技术和产品积累:1994年,公司与意法半导体首次开展战略合作,意法半导体为公司制造单芯片图形用户界面加速器;1995年,公司发布首款产品NV1;1997年,公司推出RIVA128系列产品,凭借高性能+低结构成本而广受市场好评,出货量超过100万台,在性能方面甚至优于英特尔于下一年推出的i740,而Intel则逐步退出了独立显卡市场;1998年,公司与台积电建立合作伙伴关系,自此OEM成为公司重要的销售模式;1999年,公司推出了世界第一款GPU——GeForce256,整合了关键的硬件变换和光照(T&L)、立方环境材质贴图和顶点混合、纹理压缩和凹凸映射贴图、双重纹理四像素256位渲染引擎等功能,并且兼容DirectX和OpenGL两大通用API;2000年,公司成功收购曾在1995年推出消费领域史上第一款3D图形加速卡Voodoo的图形显卡先驱3dfx。
在图形市场发展初期,面对技术及标准不成熟、行业迭代速度快且竞争激烈等难题,公司凭借“三团队-两季度”的更快速高效的研发运营模式比竞争对手更加快速地响应下游需求的变化、推出全面的产品矩阵、果断绑定大客户微软实现了份额的快速提升,从而在竞争中胜出:(1)研发上,公司采用了“三团队-两季度”的高效研发模式实现了技术和产品的快速迭代:图形市场产品研发周期包括短周期(6-9个月)和长周期(12-18个月)两类,公司则采用“三团队-两季度”的研发模式,即采用三个并行开发团队专注于第一年秋季、第二年春季、第二年秋季这三个独立的分阶段产品开发,这使得公司可以每6个月推出一次新产品,领先市场1-2个研发周期,能够更快满足下游需求的变化;(2)产品上,公司不断丰富产品矩阵:公司在GeForce256时代便通过DDR、SDR和TNT三个系列实现了高中低端的全面布局;(3)战略上,公司绑定大客户微软:NV1由于不兼容竞争3dfx的GLIDE3D主流技术标准、成本高、无性能优势因而市场表现平平,公司一度陷入破产的边缘;此时公司做出了重大决定:支持当时微软刚刚推出的Direct3D标准与GLIDE进行竞争,依靠着Windows95操作系统的高占有率,英伟达Riva128显卡出货量逐渐上升并超越3dfx,后续凭借GeForce256扩大优势并最终收购3dfx。
2.22000-2005:客户多元化,通过性能优势掌握PC独显龙头地位
GPU时代初期,大客户微软引领图形硬件标准,图形显卡双雄局面形成:2001年,微软发布了包含全新ShaderModel(优化渲染引擎模式)1.0标准的DirectX8.0,由于遵循这一接口标准的GPU具备顶点和像素的可编程性,微软开始引领图形硬件标准,图形显卡领域呈现英伟达、ATI(后被AMD收购)双寡头的局面。2001-2005年,与微软合作失败后,公司积极寻求多元客户支持,并通过产品性能再度占据PC独显龙头地位:(1)2000年公司为微软首款Xbox游戏机提供图形处理器,但因交付价格问题产生矛盾而失去了订单(改为竞争对手ATI供应),这使得公司2003年营收减少,错过了微软DirectX9规格确立的重要消息,直接导致当年推出的GeForceFX由于兼容性问题败给ATI的Radeon9700;(2)面对困境,公司积极寻求多元客户支持:1)主动与微软和解,争取再次合作;2)和Intel达成了专利交叉许可协议;3)争取到为索尼PS3游戏机开发处理器的订单、与暴雪娱乐合作发布基于3D图形世界的全球大型多人在线游戏《魔兽世界》;(3)持续迭代:2004年,公司汲取以往教训推出全新的GeFroce6800Ultra,并凭借优异的产品性能再次夺回GPU老大的地位;至2006年,ATI被AMD斥资达54亿美元收购,后续专向中低端市场,自此公司牢牢掌控了GPU高端市场并重回增长轨道;
2.32006-2015:以游戏业务筑基,培育以CUDA为核心的通用计算体系
因时机和定位失误,错失手机终端机遇:2006-2011年,以智能手机为代表的移动终端逐步兴起,2010年功能与设计理念领先业界3年的划时代产品iPhone4带来了全球智能手机渗透率的二阶导拐点,2009-2015年智能手机渗透率从14.38%提升至74.08%;公司早在2003年便开始通过收购布局移动端图像芯片,认为未来能实现通话和多媒体功能的手机将成为重要市场,此后的2008年公司依靠平板和游戏机的优势推出了针对移动端的Tegra,但由于高通凭借基带技术占据主流,而Tegra后续芯片未能及时整合基带技术而无法及时占领市场,公司因而错失了移动时代机遇,此后公司果断放弃手机市场并将Tegra处理器运用在智能汽车、智慧城市和云端服务上。
超前推出CUDA进军GPGPU,开始构建生态护城河:
(1)让只做3D渲染的GPU技术通用化:早期的GPU使用顶点着色单元和像素渲染单元两种计算资源,两种处理器数量的最佳比例是随应用的变化而变化的,因此经常出现一种处理器不够用、而另一种处理器闲置的情况,公司首席科学家DavidKirk认为给GPU装备一组完全相同的、具有较强编程能力的内核,根据任务情况在顶点和片元处理任务之间动态分配可以极大程度提升PC的计算性能,同时将丰富的并行运算资源分享给开发者,便可具备重要的战略意义,因而公司开始投入大量研发资源。
(2)坚定方向铺长路:2006年,公司推出了能够让GPU计算变得通用化的CUDA(ComputeUnifiedDeviceArchitecture)编程技术,并让公司的每一颗GPU都支持CUDA;2007年,公司推出了不具备绘图能力的第一代大规模并行运算芯片Tesla;CUDA初期投入成本较高,并给公司带来了较大的业务压力:1)在技术方面,芯片面积增大、散热增加、成本上升、故障率增高,直接导致后续G84/G86核心的产品出现了过热而导致花屏的“显卡门”事件,而公司也因此付出了近2亿美元的一次性支出代价来解决产品质量问题;2)在研发上,保证每款产品的软件驱动都支持CUDA,会对公司的工程师带来巨大的额外工作量;3)在资金上,一旦项目启动,在当时每年公司预估要在核心业务关系并不紧密的CUDA平台上投资高达5亿美元,而2006年公司总收入30.68亿美金;4)在外部环境上,2008年CPU巨头AMD收购公司对手ATI并形成了CPU整合GPU的新解决方案;Intel也终止了与英伟达的合作并在自家芯片组中集成了3D图形加速器;2008年经济危机也导致了全球PC和独显出货量同时出现了负增长;
(3)公司在内忧外困的情况下仍然坚持投入研发,研发费用逐年攀升:2009年公司推出Fermi架构的GPU,因而经营得以快速恢复,再次夺回市场领先地位,此后公司通过制程的进步及芯片设计的优化持续迭代引领行业;根据创事记,事后来看,公司在将GPU转化为更通用的计算工具上投入了将近100亿美元;
(4)通用计算价值初现,应用领域拓展:CUDA拓展了GPU的应用领域,让只做3D渲染的GPU得以从游戏(图形渲染)向外扩展至高性能计算、自动驾驶等多个领域,结合前期在游戏、移动领域的积累,公司逐步形成四大产品线:GeForce(PC、笔记本)、Quadro(工作站)、Tesla(大型高性能计算)、Tegra(移动产品);
(5)2006年以来,公司持续推进CUDA通用计算生态建设:1)架构端,公司每2年推出一个微架构,并对四大产品线进行全面升级;2)硬件端,公司2019年收购了网络芯片龙头Mellanox,并形成了CPU+GPU+DPU三芯布局;3)软件端,公司研发了大量的加速库、开发工具链,极大程度提升了易用性;最终公司形成了快速迭代的硬件+深度捆绑的软硬件+大量外围的二次开发者和易用的软件生态三位一体的生态飞轮。
终端多元化背景下,聚焦高端游戏卡稳定增长态势:2012年,平板电脑、笔记本电脑等终端的多元化使得PC出货开始呈下降趋势,同时集显性价比的逐步提升挤占了独显市场空间,公司战略聚焦高端游戏卡,通过GeForce系列站稳脚跟;根据公司披露,2010-2015年公司游戏业务收入五年CAGR达到21%,游戏显卡出货量五年CAGR为9%、ASP五年CAGR为11%,游戏业务实现了逆势增长,并为公司创造了确定的业绩增长与健康的现金流,奠定了通用GPU和AI业务爆发的基石。
2.42016至今:CUDA开花结果,云端数据中心业务开启新一轮成长曲线
2016年至今,算力需求侧经历了大数据及云服务(2016-2018)、云端办公和娱乐(2020-2021)、云端AI训练(2023至今)三大阶段,公司借助CUDA成长为全球算力龙头。
2.4.12016-2019:大数据与云服务阶段,凭借GPU的通用性登上数据中心芯片王座
大数据催生数据上云需求。2016-2018年,大数据的发展及移动互联网流量产生的海量数据催生了数据上云的需求,同时分布式编程模式MapReduce、分布存储和管理技术、虚拟化技术等关键技术的成熟使得云服务能给客户带来的的经济价值提升,海外云厂商纷纷自建大规模数据中心,2016-2017年,亚马逊、微软、谷歌、Meta四大云厂商Capex从309.62亿美元增长至405.66亿美元,资本支出同比增长31%。CUDA积累的GPU通用能力直接带来公司数据中心业务爆发。海量数据带来的计算需求激增,公司通过开发CUDA将GPU实现了通用化,2016年推出的Pascal架构的P100具备3840个CUDA核,在海量数据的并行运算上具备显著优势,公司凭借Tesla系列V100、T4、P100、P4等产品拔得头筹。在Liftr与2019年进行的调查中显示,公司的Tesla系列产品在阿里云、亚马逊AWS、微软Azure、谷歌GCP四大云厂商中的专用加速器占有率分别为82%、89%、100%和100%,呈现绝对龙头地位;根据海豚投研,公司在TOP500系统中的份额从2016年的6%迅速增长至2017年的24%,一年内增长了3倍。
2.4.22020-2022:云端办公和娱乐阶段,收购整合打造最强数据中心异构芯片+高速互联+网络安全解决方案体系护城河
卫生事件带来的云端办公和娱乐需求驱动了云厂商的第二轮数据中心建设周期,数据处理及带宽互联是关键。2020年,卫生事件导致全球生产经营和日常活动都受到了影响,催生了企业上云、人民消费娱乐上云的需求,亚马逊、微软、谷歌、Meta四大云厂商合计Capex从2020Q1至2022Q4连续12个季度保持同比20%以上的高速增长,云厂商开启了第二轮建设周期;同时,企业要求数据中心除了简单的存储以外,能够实现一定程度的数据分析,虚拟机和容器(containers)等技术的流行也使得应用程序更多放在多台服务器上进行分布式运行,这两大趋势要求未来的数据中心需要同时具备大规模数据处理能力和高带宽互连技术。收购整合构筑数据中心上下游一体的体系化护城河。公司于2019年斥资69亿美金收购了InfiniBand和以太网领军Mellanox,而Mellanox则在2020年收购了网络安全和智能IP提供商TitanIC,该套娃式收购大大提升了公司云端AI产品体系的竞争力,将公司在单机上的生态优势成功拓展到了分布式集群中:分布式训练对于数据交互的需求非常高,而Mellanox的数据互联方案+英伟达的GPU底层接口可以成为完善的工程解决方案,TitanIC提供的网络安全和内容智能又能够实现在硬件加速器中检测恶意入侵的网络流量并减少了CPU负载,最终公司构建起了包含人工智能芯片及生态+高速数据互联解决方案+网络安全加速的横跨多个领域的完整方案。DPU专为减少CPU负荷、进一步提升大规模数据中心系统效率而生。数据大爆发的时代,仍存在CPU处理效率低下、GPU处理不了的负载,如网络虚拟化、硬件资源池化等基础设施层服务,DPU可作为CPU的卸载引擎,通过承担网络、存储、安全等业务,提升整个计算系统的效率、降低整体系统的总体拥有成本(TCO)。
公司集成CPU+GPU+DPU形成三芯异构硬件布局,实现数据中心芯片体系的“降本增效”。公司在2020年凭借Mellanox原有的ConnectX系列高速网卡技术,推出了DPU(数据处理器)BlueField-2,并在2021年推出了匹配的DOCA(Data-Center-InfrastructrueOn-A-Chip-Architectrue,即“线上数据中心基础设施体系结构”)生态,BlueField系列DPU在支持网络处理、安全和存储功能的同时,实现网络虚拟化、硬件资源池化等基础设施层服务,同时可释放高达30%的CPU资源;而DOCA软件框架使开发者能够在BlueFieldDPU上快速创建应用程序和服务,为开发者构建软件定义、硬件加速网络、存储、安全和其他基础设施应用程序提供了一个全面的开放平台。
2.4.32023至今:大模型浪潮引爆公司数据中心业务成长
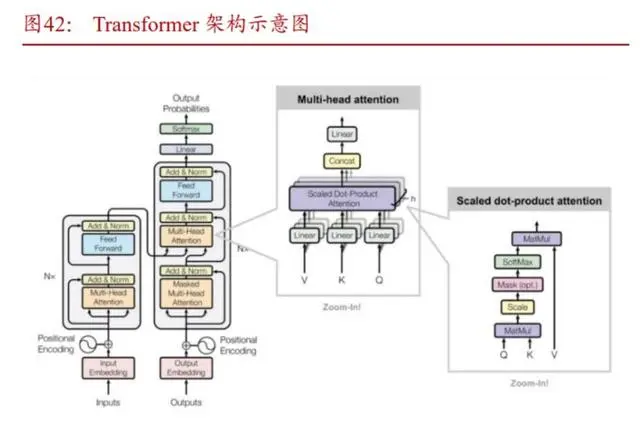
GPT本质是基于Transformer架构的大模型。GPT,全称”GenerativePre-trainingTransformer”,最初是一个由OpenAI开发的自然语言处理(NLP)的模型,通过预训练和生成技术以及Transformer的自注意力机制,可以理解和生成人类的自然语言,比传统的RNN、CNN更快、更稳定、准确率更高、回答更富有逻辑性、并具备强大的泛化能力。
大模型对于算力的需求体现在模型训练和推理应用两个阶段:
(1)训练阶段:根据OpenAI的论文《ScalingLawsforNeuralLanguageModels》(2020年发表),训练阶段算力需求=3×前向传递操作数×模型参数数量×训练集规模,训练所需GPU数量=总算力需求/(每个GPU每秒运算能力×训练时间×有效算力比率),因此我们可以得到,单次训练GPT-4需要约2.65万张A100。
(2)推理阶段:同样根据openAI论文可以得到,单次GPT-4推理所需要的算力成本约为0.05美分,按照AIPRM统计,截至2023年12月,ChatGPT拥有约1.8亿用户,平均每月产生17亿次网站浏览量,则平均每天访问次数为567万次,假设每次访问进行10轮推理对话,则平均每秒进行推理次数为17/30*10/3600*10^8≈157407次,对应GPT-4需要A100为27.7万张。
大模型引爆算力需求。根据IDC预计,数据中心GPU市场预计将从2022年的103亿美元增长至2027年的654亿美元,CAGR达到44.55%;AMD报告显示,2023年全球AI芯片市场规模会达450亿美元左右,预计2027年将增长到4000亿美元,2023年-2027年复合增速超过70%。
公司凭借数据中心产品和生态体系一飞冲天。公司2023Q3-2023Q4,数据中心业务收入分别达到145.14、184.04亿,同比增速达到278.66%、408.96%;截至2024年3月27日,市值达到2.3万亿美元,较2023年初涨幅超过530%。
顺势而为切入云端定制ASIC。由于算力成本高企,云计算公司纷纷开始自研芯片以部分替代英伟达产品,根据财联社,2月9日消息人士透露,英伟达正在建立一个新的业务部门,专注于为云计算等公司设计定制芯片以及先进的人工智能(AI)处理器;我们认为公司此举既能减少客户自研芯片带来的替代压力,又能为长期芯片走向降本化、定制化提前做好准备。我们认为,从10年维度下的长期视角来看,单位算力成本的下降是确定的趋势,根据CSET报告《AIChips:WhatTheyAreandWhyTheyMatter》,与GPU相比,ASIC芯片在训练上的效率平均约为10倍、推理上的效率约为100倍,因而随着大模型的发展逐步进入成熟期,ASIC的芯片市场规模有望逐步提升,根据研究公司650Group的AlanWeckel的估计,数据中心定制芯片市场今年将增长到高达100亿美元,到2025年将翻一番。
前瞻布局移动基站,剑指边缘计算。根据新浪财经、财联社,英伟达正在与电信基础设施建设者爱立信就一款包含芯片设计公司的图形处理单元(GPU)技术的无线芯片进行谈判,同时软银和英伟达将联合成立一个新的行业协会“AI-RAN联盟”,电信巨头爱立信、诺基亚等全球约10家公司也将参加其中,致力于将利用移动通信基站分散AI处理的技术实用化。我们认为长期看,未来AI算力增量需求场景将逐步由云向边缘、端侧转移,公司有望在边缘侧复制云端的成功经验。根据TDIA预计,2023年底全球5G基站将突破480万个,650Group的Weckle预计电信定制芯片市场每年约为40亿至50亿美元。
三、巨头成长之路总结:专注带来前瞻,通用诞生生态
3.1专注计算芯片,带来前瞻战略思维
专注GPU,保持高强度研发投入。英伟达以图形处理器起家,1999年,英伟达发布了世界上第一个正式的GPU——GeForce256。随后,公司持续加大研发投入,深耕GPU领域,无论是游戏显卡、数据中心加速卡、自动驾驶芯片、可视化领域,英伟达不断推展产品终端用户群体的同时,始终保持GPU产品的研发和迭代。公司研发费用率常年保持在20%-30%,同时随着营收规模的增长,研发人员以及研发金额也不断攀升。
“三团队两季度”驱动创新。英伟达成立伊始,为了应对图形芯片市场激烈的竞争,采用“三团队两季度”的研发策略,将研发团队分为产品、硬件、软件三个团队,每个团队专注于自身负责领域以保证产品创新性,同时两季度研发模式保证公司每六个月迭代一次产品,领先市场研发周期的同时,充分满足下游市场需求。产品端:专注游戏显卡领域竞争,迎合玩家需求快速迭代产品。2010年后,英伟达和AMD逐渐抢占其他公司份额,成为独立显卡领域唯二的巨头。随后在游戏显卡领域,英伟达加速产品迭代速度以及性价比的提升,逐步提升市场份额,截止2023Q3,英伟达独立显卡市场份额达到81.50%。我们认为,正是公司专注于GPU研发,带来了游戏显卡的快速迭代以及性价比的快速提升,牢牢抓住玩家需求,最终成长为市场龙头。
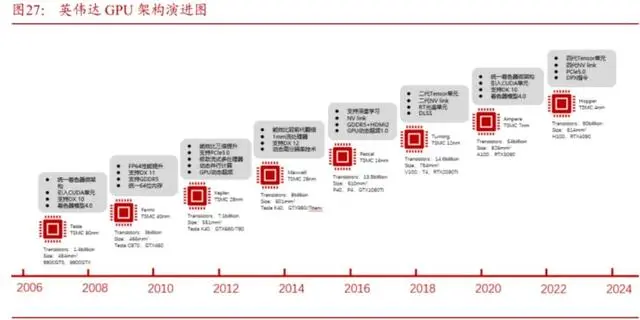
微架构创新,从底层突破GPU性能与效率。公司自2006年自研的Tesla架构开始。不断更新GPU架构,平均两年迭代一次GPU架构。目前公司旗舰产品采用Hopper架构,采用台积电4nm制程,下一代游戏显卡RTX50系产品以及数据中心产品B100将采用Blackwell架构,将使用台积电的4nm工艺,与现有采用Hopper架构的H200系列相比,性能提升超过100%。公司GPU架构发展历程详见图27。前瞻性:预见CUDA生态的革命性。英伟达于2006年开发CUDA,从今天的眼光来看,这项决策领先了市场十年之久,对比另一家GPU巨头AMD,AMD于2015年为了对标CUDA生态开发了ROCm,落后英伟达9年。
3.2注重技术复用性,让研发投入落到实处
决策高效干脆,放弃手机芯片市场。2008年公司依靠平板和游戏机的优势推出了针对移动端的Tegra,但由于高通凭借基带技术占据主流,而Tegra后续芯片未能及时整合基带技术而无法及时占领市场,公司因而错失了移动时代机遇,此后公司果断放弃手机市场并将Tegra处理器运用在智能汽车、智慧城市和云端服务上。
技术复用,开辟汽车芯片市场。2015年国际消费类电子产品展览会上,英伟达发布新一代移动超级芯片TegraX1处理器,该处理器在性能上是上一代产品TegraK1的两倍。该处理器适配NVIDIADRIVEPX汽车自动驾驶计算平台,可处理来自12个车载摄像头的视频,以实现环绕视觉(Surround-Vision)和自动代客泊车(Auto-Valet)等功能。虽然英伟达在移动芯片领域折戟沉沙,但其技术上极强的复用性,最终使其成功转向至汽车芯片领域。
3.3重视通用性,引入生态共建
GPGPU:通用化漫漫长路。GPU一开始只是为了图形加速,替CPU分担工作。其主要用于显示图像、视频的编解码与显示、游戏渲染等工作,起初并不支持编程。在1999年之前甚至没有GPU这一概念,只是称为图形加速卡。英伟达发现了GPU在并行计算方面的优势,并且在科学、工程和人工智能领域,许多问题都可以通过并行计算来加速解决。
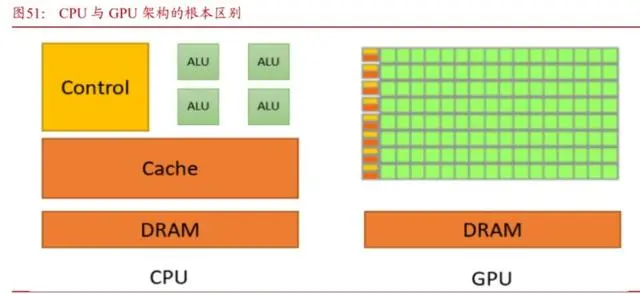
CUDA出现之前,GPU的编程面临多重挑战:1)编程模型不足:没有一种通用的编程模型来利用GPU的计算能力。开发人员需要使用低级别的图形API(如OpenGL或Direct3D)来执行计算任务。这些API并不专门用于通用计算,因此编写代码变得复杂且容易出错。2)数据传输成本高:将数据从CPU传输到GPU的成本很高。这涉及到数据的复制和传输,而这些操作会降低性能。3)无法发挥并行性:开发人员需要手动管理GPU并行性,这对于复杂的计算任务来说是巨大的人力成本。降低开发者门槛,让GPU真正意义上“可编程”。在经GPU加速的应用中,工作负载的串行部分在CPU上运行,且CPU已针对单线程性能进行优化,而应用的计算密集型部分则以并行方式在数千个GPU核心上运行。使用CUDA时,开发者使用主流语言(如C、C++、Fortran、Python和MATLAB)进行编程,并通过扩展程序以几个基本关键字的形式来表示并行性。英伟达的CUDA工具包提供了开发GPU加速应用所需的一切。TensorRT基于CUDA平台并行编程模型构建,使开发者能够在英伟达GPU产品上使用量化、层和张量融合、内核调整等技术来优化推理。TensorRT是英伟达基于CUDA一款用于高性能深度学习推理的SDK(SoftwareDevelopmentKit),使用门槛相对较低,可以运用C++、PythonAPI导入和加速模型。
TensorRT在低门槛开发的同时,能够最大化挖掘GPU性能。NVIDIATensorRT-LLM是一个开源库,可加速和优化NVIDIAAI平台上最新大型语言模型(LLM)的推理性能,而无需深入了解C++或CUDA。
CUDA平台允许开发者利用英伟达的GPU来加速计算密集型任务。在全球范围内,许多行业领军者采用CUDA平台最大化其GPU性能。
我们认为,正是公司CUDA低门槛的特性、GPU过硬的性能,引入了大批开发者建设CUDA生态社区,最终CUDA绑定了数百万AI开发者,当CUDA几乎与AI画等号的时候,会有大量的社区力量为其助力。这就是一种良性循环:好的性能带来好的生态,好的生态会有助于更好的性能。最终帮助英伟达构建了强大的CUDA生态护城河。
四、国内相关公司:逐步追赶,国产化趋势已现
4.1华为昇腾:对标英伟达,有望成为国内第二
AI算力生态昇腾处理器支持全场景。昇腾处理器是全球首个覆盖全场景AI芯片,基于统一的达芬奇架构,可以支持端边云不同场景的差异化算力需求,并具备从几十毫瓦IP到几百瓦芯片的平滑扩展,覆盖了端边云全场景部署的能力:
昇腾910训练处理器具有超高算力,FP16下性能最高可达320TFLOPS。昇腾910集成了CPUCore、DVPP和任务调度器(TaskScheduler),可以减少和HostCPU的交互,充分发挥其高算力的优势;还集成了HCCS、PCle4.0和ROCEv2接口,为构建横向扩展(ScaleOut)和纵向扩展(ScaleUp)系统提供了灵活高效的方法,科大讯飞创始人、董事长刘庆峰表示华为的GPU能力可以对标英伟达A100;
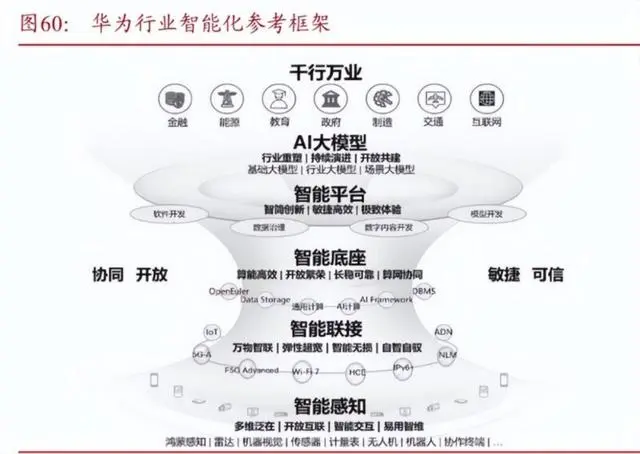
华为昇腾AI产业生态包括昇腾AI基础软硬件平台,即Atlas系列硬件、异构计算架构CANN、全场景AI框架昇思MindSpore、昇腾应用使能MindX以及一站式开发平台ModelArts等。基于昇腾910系列板卡,华为推出了AI训练集群Atlas900、AI训练服务器Atlas800、智能小站Atlas500、AI推理与训练卡Atlas300和AI加速模块Atlas200,完成了Atlas全系列产品布局,支持万亿参数大模型训练,同时覆盖云、边、端全场景。华为提出了具备分层开放、体系协同、敏捷高效、安全可信等特征的,全行业通用的行业智能化参考架构。其中智能底座提供大规模AI算力、海量存储及并行计算框架,支撑大模型训练,提升训练效率,提供高性能的存算网协同。根据场景需求不同,提供系列化的算力能力。适应不同场景,提供系列化、分层、友好的开放能力。另外,智能底座层还包含品类多样的边缘计算设备,支撑边缘推理和数据分析等业务场景。
4.2海光信息:类CUDA带来更好的生态兼容性
海光DCU属于GPGPU的一种。性能上,海光深算一号DCU内核频率、显存位宽已逐步接近英伟达A100,在显存容量、带宽、算力、互联性能上仍有一定的进步空间;深算二号已于2023年Q3发布,实现了在大数据处理、人工智能、商业计算等领域的商业化应用,具有全精度浮点数据和各种常见整型数据计算能力,性能相对于深算一号实现了翻倍的增长;深算三号研发进展顺利。
在AIGC持续快速发展的时代背景下,海光DCU能够完整支持大模型训练,实现LLaMa、GPT、Bloom、ChatGLM、悟道、紫东太初等为代表的大模型的全面应用,与国内包括文心一言等大模型全面适配,达到国内领先水平。
DCU产品具备完善的软件栈支持。海光DCU协处理器全面兼容ROCmGPU计算生态,由于ROCm和CUDA在生态、编程环境等方面具有高度的相似性,CUDA用户可以以较低代价快速迁移至ROCm平台,因此ROCm也被称为“类CUDA”。因此,海光DCU协处理器能够较好地适配、适应国际主流商业计算软件和人工智能软件,软硬件生态丰富,可广泛应用于大数据处理、人工智能、商业计算等计算密集类应用领域,主要部署在服务器集群或数据中心,为应用程序提供高性能、高能效比的算力,支撑高复杂度和高吞吐量的数据处理任务。海光DCU具备开放式生态和统一底层硬件驱动平台,支持常见计算框架、库和编程模型层次化软件栈,适配不同API接口和编译器可最大限度利用已有的成熟AI算法和框架。
4.3寒武纪:云端芯片性能持续扩展,云边终端协同覆盖
云端AI推理,高能效比国产芯片。思元270集成了寒武纪在处理器架构领域的一系列创新性技术,处理非稀疏人工智能模型的理论峰值性能提升至上一代思元100的4倍,达到128TOPS(INT8);同时兼容INT4和INT16运算,理论峰值分别达到256TOPS和64TOPS;支持浮点运算和混合精度运算。思元270采用寒武纪MLUv02架构,可支持视觉、语音、自然语言处理以及传统机器学习等多样化的人工智能应用,更为视觉应用集成了充裕的视频和图像编解码硬件单元。推理卡研发迭代,性能持续提升。思元370是寒武纪首款采用chiplet(芯粒)技术的AI芯片,集成了390亿个晶体管,最大算力高达256TOPS(INT8),是寒武纪第二代产品思元270算力的2倍。凭借寒武纪最新智能芯片架构MLUarch03,思元370实测性能表现更为优秀。思元370也是国内第一款公开发布支持LPDDR5内存的云端AI芯片,内存带宽是上一代产品的3倍,访存能效达GDDR6的1.5倍。搭载MLU-Link™多芯互联技术,在分布式训练或推理任务中为多颗思元370芯片提供高效协同能力。全新升级的寒武纪基础软件平台,新增推理加速引擎MagicMind,实现训推一体,大幅提升了开发部署的效率,降低用户的学习成本、开发成本和运营成本。
先进工艺保障芯片制造。公司已掌握7nm等先进工艺下开展复杂芯片物理设计的一系列关键技术,并且已将其成功应用于思元100、思元220、思元270、思元290、思元370等多款芯片的物理设计中。
4.4景嘉微:发布景宏系列高性能计算产品,商业化布局有望加速
公司是国内首家成功研制国产GPU芯片并实现大规模工程应用的企业,掌握了包括芯片底层逻辑/物理设计、超大规模电路集成验证、模拟接口设计、GPU驱动程序设计等关键技术,2010年,公司自研GPU项目获得国家“核高基”专项支持。2014年研发JM5400,2018年研发JM7200。公司在GPU体系结构、图形绘制高效处理算法、高速浮点运算器设计、可复用模块设计、快速大容量存储器接口设计、低功耗设计等方面有深厚的技术积累,先后研制成功JM5系列、JM7系列、JM9系列等具有自主知识产权的高性能GPU芯片。2024年3月,公司披露景宏系列产品研发进展。景宏系列是公司推出的面向AI训练、AI推理、科学计算等应用领域的高性能智算模块及整机产品,支持INT8、FP16、FP32、FP64等混合精度运算,支持全新的多卡互联技术进行算力扩展,适配国内外主流CPU、操作系统及服务器厂商,能够支持当前主流的计算生态、深度学习框架和算法模型库,大幅缩短用户适配验证周期。