DeepSeek V4 深度解析:开源模型的新王座
来源:程序员行一 | 发布时间:2026-04-30
摘要:DeepSeek V4 是一次架构驱动的重大突破,其核心是DSA稀疏注意力机制,它在计算上实现巨大优化,使得1M上下文成为标配,并为模型带来了全面的能力提升。开源是V4的战略核心,其代码能力在多项基准测试中登顶,并在Agent体验上达到可对标顶级闭源模型的水平,同时通过支持华为算力等举措,构建了一个强大而开放的生态系统。
核心结论
2026年4月24日,DeepSeek V4 预览版正式发布并同步开源。这是继 V3(2024年12月)之后,时隔15个月的重大版本更新。
一句话总结:V4 用架构创新把 1M 上下文打成了标配,Agent 能力比肩 Sonnet 4.5,代码能力登顶 LiveCodeBench,且 Pro 版计算量比上代降低 3.7 倍。
两个版本同步上线:
- V4-Pro:1.6T 总参、49B 激活参数,性能对标顶级闭源模型
- V4-Flash:284B 总参、13B 激活参数,更小更快的经济版
这也是 DeepSeek 首次在发布稿中直接披露内部使用情况——员工已将 V4 作为主力 Agentic Coding 模型,体验优于 Sonnet 4.5。
一、15个月的等待,V4 带来了什么
回顾一下 V3.2 时代:128K 上下文,MoE 架构,在开源模型中称王,但在世界知识、长上下文、Agent 能力上跟闭源头部仍有肉眼可见的差距。V4 几乎是针对每一个短板做了定向突破。
长上下文:1M token 上下文成为所有服务的标配。一年前这还是 Gemini 独占的王牌功能,现在 V4 直接把门槛踩平了。
世界知识:官方数据,V4-Pro 在世界知识评测中「大幅领先其他开源模型,仅稍逊于顶尖闭源模型 Gemini-Pro-3.1」。V3.2 时代的事实问答(SimpleQA)只有 28.3,V4-Pro 直接拉到 55.2,涨了 26.9 分——几乎翻倍。
Agent 能力:这是 V4 投入最大的方向。发布稿明确写了,V4 针对 Claude Code、OpenClaw、OpenCode、CodeBuddy 等主流 Agent 产品做了适配和优化。内部评测中,V4 的 Agent Coding 体验优于 Sonnet 4.5,交付质量接近 Opus 4.6 非思考模式。
代码能力:LiveCodeBench 93.5 分,在当天的评测矩阵中排名第一。Apex Shortlist 90.2,Codeforces 3206——每一项都进入了第一梯队。
这几个方向背后,真正支撑一切的是架构层面的创新。
二、DSA 稀疏注意力:V4 的地基
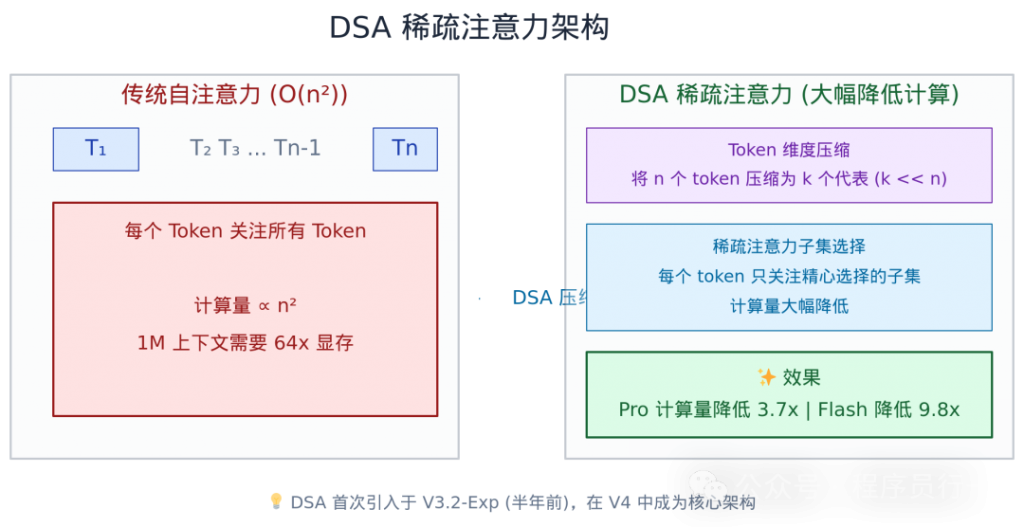
如果说 V4 有一个关键词,那就是 DSA(DeepSeek Sparse Attention)。
这不是发布当天才冒出来的东西。半年前 V3.2-Exp 那次更新首次引入了 DSA,当时外界关注度不高——因为跑分跟 V3.1-Terminus 几乎一样,看起来像一次”没什么料的中间版本”。现在回头看,那次 Exp 版本就是 V4 的地基。
V4 在 DSA 基础上进一步开创了一种全新的注意力机制——在 token 维度进行压缩。具体来说,Transformer 的自注意力计算复杂度是 O(n²),其中 n 是序列长度。当上下文从 128K 扩展到 1M 时,naive 自注意力的计算量和显存需求会暴涨约 64 倍。
DSA 的做法是:不是每个 token 都要关注所有 token。通过稀疏注意力模式,每个 token 只关注一个精心选择的子集,同时在 token 维度对表示进行压缩,从而在不显著损失精度的前提下大幅降低计算开销。
官方给出的数据:
- V4-Pro 单 token 计算量(FLOPs)比 V3.2 降低 3.7 倍
- V4-Flash 比 V3.2 降低 9.8 倍
这是什么概念?同样的显卡、同样的显存,可以处理更多的并发请求。对大模型服务商来说,这意味着单卡吞吐量直接翻几倍。对开发者来说,意味着推理延迟更低、成本更低。
DSA 的另一层意义在于,它让 1M 上下文从高端功能变成了水电煤。以前长上下文是高配版专属,现在官方服务全部标配 1M。代码仓库级别的理解、超长文档分析、多轮 Agent 对话的场景连续性——这些以前受限于上下文长度的能力,现在都是标配能力。
三、思考模式:从一刀切到精细控制
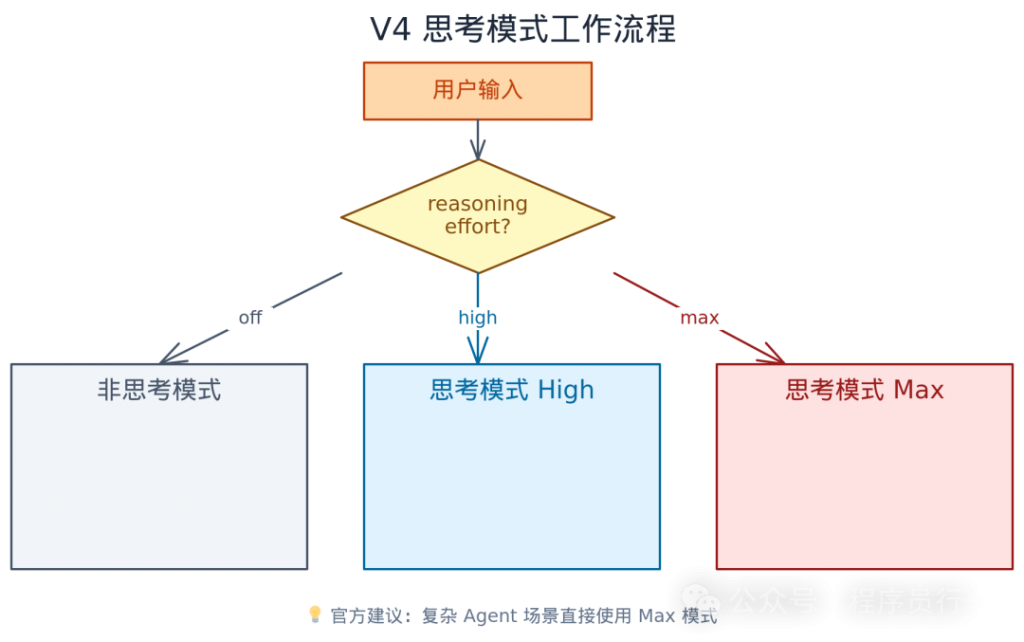
V4 对推理能力的控制也更加精细。两个版本都同时支持非思考模式和思考模式,思考模式下通过 reasoning_effort 参数调节强度,提供 high 和 max 两档。
非思考模式:适用于常规对话、简单问答、文本生成等不需要深度推理的场景。响应速度最快,成本最低。
思考模式(Thinking Mode):模型在输出最终回答之前,会先进行隐式推理。这个过程对用户不可见(不暴露 CoT 原文),但能显著提升数学、代码、逻辑推理等复杂任务的质量。
reasoning_effort 参数:
high:推理强度较高,适用于中等复杂度的推理任务max:最大推理强度,官方建议”复杂 Agent 场景直接上 max”
这是一个实用导向的设计。不需要推理的场景用非思考模式省钱省时间;需要推理的场景按复杂度选 high 或 max,而不是一刀切。对比一些竞品要么全开要么全关的做法,V4 的思考模式给了开发者真正的灵活度。
实际调用很简单。以 OpenAI 兼容接口为例:
curl https://api.deepseek.com/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $DEEPSEEK_API_KEY" \
-d '{
"model": "deepseek-v4-pro",
"messages": [
{"role": "user", "content": "实现一个分布式一致性算法"}
],
"thinking": {"type": "enabled"},
"reasoning_effort": "max"
}'同时支持 Anthropic 格式接口,base_url 改为 https://api.deepseek.com/anthropic 即可。
四、性能实测:开源对阵闭源
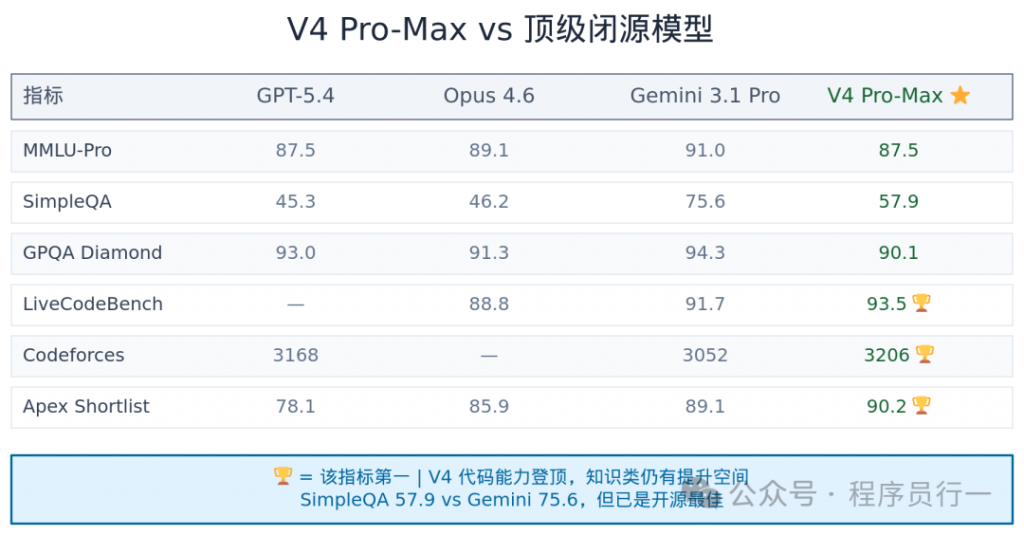
光说创新不说跑分就是耍流氓。来看 V4 Pro-Max(开启 max 推理强度)与当前顶级模型的横向对比:
| 指标 | GPT-5.4 | Claude Opus 4.6 | Gemini 3.1 Pro | V4 Pro-Max |
|---|---|---|---|---|
| MMLU-Pro | 87.5 | 89.1 | 91.0 | 87.5 |
| SimpleQA | 45.3 | 46.2 | 75.6 | 57.9 |
| GPQA Diamond | 93.0 | 91.3 | 94.3 | 90.1 |
| LiveCodeBench | — | 88.8 | 91.7 | 93.5 |
| Codeforces | 3168 | — | 3052 | 3206 |
| Apex Shortlist | 78.1 | 85.9 | 89.1 | 90.2 |
三条核心观察:
1. 代码能力是 V4 的杀手锏。 LiveCodeBench 93.5 排名第一,Apex Shortlist 90.2 碾压全场,Codeforces 3206 —— 三个代码类指标全部登顶。对于一个开源模型来说,这是历史性突破。
2. 推理与知识仍有提升空间。 MMLU-Pro 87.5 略低于 Opus 4.6 的 89.1 和 Gemini 3.1 Pro 的 91.0。事实问答 SimpleQA 57.9,虽然比 V3.2 的 28.3 翻了一倍多,但跟 Gemini 的 75.6 差距明显。这说明 V4 在”知道什么是对的”方面已经赶上,但在”记住大量事实”方面仍是追赶者。
3. 全面对标,不偏科。 没有哪一个指标出现崩盘。即使是短板的 SimpleQA,也是 57.9 vs Gemini 75.6 的差距,而不是几倍的差距。这比 V3.2 时代”代码强知识弱”的偏科局面改善了很多。
再看 V3.2 到 V4 的代际提升:
| 类别 | 指标 | V3.2 | V4-Pro | 提升 |
|---|---|---|---|---|
| 知识 | MMLU-Pro | 65.5 | 73.5 | +8.0 |
| 事实 | SimpleQA | 28.3 | 55.2 | +26.9 |
| 代码 | HumanEval | 62.8 | 76.8 | +14.0 |
| 长文本 | LongBench-V2 | 40.2 | 51.5 | +11.3 |
| 数学 | MATH | 60.5 | 64.5 | +4.0 |
事实问答涨了 26.9 分,代码涨了 14 分——这两个维度的提升幅度远超常规代际更新,背后是 DSA 架构对长上下文信息捕捉能力的质变。
五、API 价格与迁移指南
API 价格是开发者最关心的。这次定价策略是”Flash 降价、Pro 涨价”:
| 模型 | 输入(缓存命中) | 输入(未命中) | 输出 | 上下文 |
|---|---|---|---|---|
| V3.2 | 0.2 元 | 2 元 | 3 元 | 128K |
| V4 Flash | 0.2 元 | 1 元 | 2 元 | 1M |
| V4 Pro | 1 元 | 12 元 | 24 元 | 1M |
注:价格为每百万 token,人民币。
V4 Flash 全面降价(输入降 50%,输出降 33%),上下文还从 128K 翻到 1M——经济版实至名归。V4 Pro 大幅涨价,但考虑到 1M 上下文 + thinking mode 的能力,这个定价瞄准的是对质量有要求的 Agent 和企业级场景。
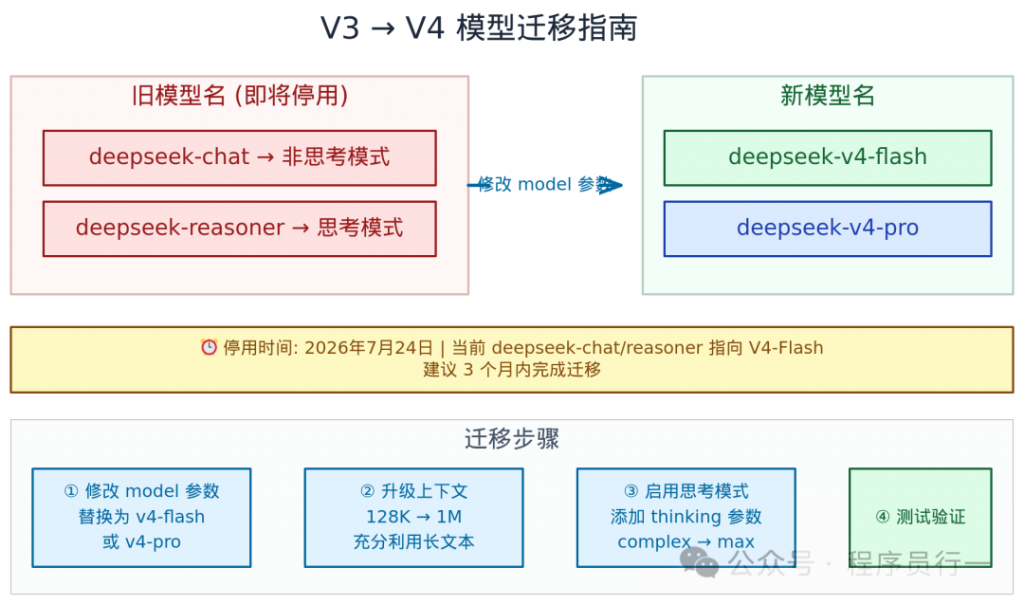
重大变更:deepseek-chat 和 deepseek-reasoner 这两个旧模型名将于 2026年7月24日 停用。当前这两个名称分别指向 V4-Flash 的非思考和思考模式。停用后,必须显式指定 deepseek-v4-pro 或 deepseek-v4-flash。
迁移步骤非常简单:
- 修改 API 请求中的
model参数:deepseek-chat→deepseek-v4-flash(非思考)deepseek-reasoner→deepseek-v4-flash+thinking: enabled
- 如果需要高质量推理,升级到
deepseek-v4-pro - 如果有自定义的模型名映射,更新配置
- 测试验证,确认行为和输出质量符合预期
国产算力路线
发布稿中提到一个重要信息:下半年支持华为算力。这意味着 V4 的部署方案将不局限于 NVIDIA 生态,为国内企业提供了合规、可控的算力选择。在当前的国际环境下,这条路径的战略意义不亚于模型性能本身。
六、开源生态与社区反应
V4 延续了 DeepSeek 一贯的开源策略,模型权重和技术报告同步公开:
- HuggingFace:
deepseek-ai/DeepSeek-V4合集 - ModelScope:
deepseek-ai/DeepSeek-V4合集 - 技术报告 PDF:随模型权重一同发布
发布稿末尾引用了荀子《非十二子》中的一句话:
不诱于誉,不恐于诽,率道而行,端然正己。
翻译成大白话:不被赞誉诱惑,不被诽谤吓到,按自己认定的路走,端正自己。
过去半年,关于 V4″什么时候发””是不是跳票””是不是被超越了”的传言在中文和英文 AI 圈反复横跳。有说春节前发的,有说被 Claude 蒸馏数据搞定的。DeepSeek 一次都没回应。然后在某个周五下午,同步放出模型、开源权重、上线官网和 API、顺便把员工已弃用 Claude 的事实写进发布稿。
没有路线图,没有直播,没有访谈。率道而行。
总结
DeepSeek V4 不是 V3 的简单升级,而是一次架构层面的重造。DSA 稀疏注意力让 1M 上下文成为标配,同时大幅降低了计算成本;Agent 能力首次进入”可以替代闭源模型”的讨论范围;代码能力登顶多个榜单。
当然也有不足——世界知识(SimpleQA)跟 Gemini 还有明显差距,推理类指标(MMLU-Pro、GPQA Diamond)跟最顶尖闭源模型仍有毫厘之差。但考虑到这是一个开源模型,且 Pro 版的计算效率比上代提升了 3.7 倍,这个性价比是闭源模型无法企及的。
对于开发者:
- 轻度使用、成本敏感:V4 Flash,1M 上下文只要白菜价
- 高质量推理、Agent 开发:V4 Pro + thinking max,对标顶级闭源
- 现有 V3 用户:三个月窗口期迁移模型名,建议趁早适配
如果说 V3 证明了开源可以追上闭源,那 V4 证明的是:开源可以在特定赛道上实现超越。